クラスのインスタンスがクラスインスタンス生成式によって生成される時,クラスが インスタンス化 されたと呼ぶ。 クラスのインスタンス化は,インスタンス化するクラス,新たに作成したインスタンスの取囲みインスタンス(存在するならば),新しいインスタンスを生成するために呼び出さねばならないコンストラクタ,及びそのコンストラクタに渡さねばならない実引数の決定を含む。
15.9.1 インスタンス化されるクラスの決定
もしクラスインスタンス生成式がクラス本体で終了するならば,インスタンス化されたクラスは匿名クラスとする。 したがって,次のように決定される。
- もしクラスインスタンス生成式が,非限定クラスインスタンス生成式であるならば,T が新しいトークンの後の ClassOrInterfaceType であると仮定する。
もし,T によって命名されたクラス又はインタフェースがアクセス不可能(6.6)ならば,コンパイル時エラーが発生する。
もし T がクラスの名前であるならば,T によって命名されたクラスの匿名の直接的下位クラスが宣言される。
もし T によって命名されたクラスが
finalクラスであるならば,コンパイル時エラーが発生する。 もし T がインスタンスの名前であるならば,T によって命名されたインタフェースを実装したObjectの匿名の直接的下位クラスが宣言される。 どちらの場合も,下位クラスの本体はクラスインスタンス生成式の中で定められた ClassBody とする。 - そうでなければ,クラスインスタンス生成式は,限定クラスインスタンス生成式とする。
T が新しいトークンの後の Identifier の名前であると仮定する。
もし T がアクセス可能な(6.6) Primary のコンパイル時型のメンバである非
finalの内部クラス(8.1.2)の単純名ではない場合,コンパイル時エラーが発生する。 もし T があいまい(8.5)であるならば,コンパイル時エラーが発生する。 T によって命名されたクラスの匿名の直接的下位クラスが宣言される。 サブクラスの本体は,クラスインスタンス生成式の中で定められた ClassBody とする。 インスタンス化されたクラスは,匿名下位クラスとする。
-
もしクラスインスタンス生成式が非限定クラスインスタンス生成式であるならば,ClassOrInterfaceType は,アクセス可能(6.6)で,かつ
abstractではないクラスを命名しなければならない。そうでなければ,コンパイル時エラーが発生する。 この場合,インスタンス化されたクラスは ClassOrInterfaceType で指示される。 -
そうでなければ,クラスインスタンス生成式は限定クラスインスタンス生成式とする。
もし Identifier が Primary のコンパイル時型のメンバであるアクセス可能(6.6)な非
abstract内部クラス(8.1.2)Tの単純名(6.2)でないならば,コンパイル時エラーが発生する。 もし Identifier があいまい(8.5)ならば,この場合もまたコンパイル時エラーが発生する。 インスタンス化されたクラスは,Identifier で指示される。
15.9.2 取囲みインスタンスの決定
C がインスタンス化されたクラスであり及び i が生成されたインスタンスであると仮定する。 もし,C が内部クラスであるならば,i は直接的に取り囲むインスタンスを持ってよい。 i の直接的に取り囲むインスタンス(8.1.2)は,次のように決定される。
- もし C が匿名クラスならば,次のように決定される。
- もしそのクラスインスタンス生成式が静的文脈(8.1.2)の中に現れるならば,i は直接的に取り囲むインスタンスを持たない。
- そうでなければ,i の直接的に取り囲むインスタンスは
thisとする。
- C が局所クラス(14.3)であるならば,C は字句的に取り囲むクラス O の中で宣言されたメソッドの中で宣言されねばならない。
n が整数であると仮定する。
O がそのクラスインスタンス生成式が現れるクラスの中の n 番目の字句的に取り囲むクラスであるというように,n は整数であると仮定する。
それならば,
- もし C が静的文脈の中に現れるならば,i は直接的に取り囲むインスタンスを持たない。
- そうでなければ,もしそのクラスインスタンス生成式が静的文脈の中に現れるならば,コンパイル時エラーが発生する。
- そうでなければ,i の直接的に取り囲むインスタンスは,
this(8.1.2)の n 番目の字句的に取り囲むインスタンスとする。
- そうでなければ,C は内部メンバクラス(8.5)とする。
- もし,そのクラスインスタンス生成式が非限定クラスインスタンス生成式であるならば,
- もしそのクラスインスタンス生成式が静的文脈の中に現れるならば,コンパイル時エラーが発生する。
- そうでなければ,もし C が取囲みクラスのメンバであるならば,O は C がメンバである最内の字句的に取り囲むクラスであり及び O がそのクラスインスタンス生成式が現れるクラスの n 番目の字句的に取り囲むクラスであるというように,n は整数であると仮定する。
i の直接的に取り囲むインスタンスは,
this.の n 番目の字句的に取り囲むインスタンスとする。 - そうでなければ,コンパイル時エラーが発生する。
- そうでなければ,そのクラスインスタンス生成式は限定クラスインスタンス生成式とする。 i の直接的に取り囲むインスタンスは,Primary 式の値であるオブジェクトとする。
- もし,そのクラスインスタンス生成式が非限定クラスインスタンス生成式であるならば,
- もし S が局所クラス(14.3)であるならば,S は字句的に取り囲むクラス O の中で宣言されるメソッドの中で宣言しなければならない。
O がそのクラスインスタンス生成式が現れるクラスの n 番目の字句的に取り囲むクラスであるというように,n は整数であると仮定する。
それならば,
- もし S が静的文脈の中に現れるならば,i は S に関しては直接的に取り囲むインスタンスを持たない。
- そうでなければ,もしそのクラスインスタンス生成式が静的文脈の中で現れるならば,コンパイル時エラーが発生する。
- そうでなければ,S に関しては i の直接的に取り囲むインスタンスは,
thisの n 番目の字句的に取り囲むインスタンスとする。
- そうでなければ,S は内部メンバクラス(8.5)とする。
- もしクラスインスタンス生成式が,非限定クラスインスタンス生成式ならば,
- もし,そのクラスインスタンス生成式が静的文脈の中に出現するならば,コンパイル時エラーが発生する。
- そうでなければ,もし S が取囲みクラスのインスタンスであるならば,O はS がメンバである最内の字句的に取り囲むクラスであり及び O がそのクラスインスタンス生成式が現れるクラスの n 番目の字句的に取り囲むクラスであるというように,n は整数であると仮定する。
S に関しては i の直接的に取り囲むインスタンスは,
thisの n 番目の字句的に取り囲むインスタンスとする。 - そうでなければ,コンパイル時エラーが発生する。
- そうでなければ,そのクラスインスタンス生成式は,限定クラスインスタンス生成式とする。 S に関しては i の直接的に取り囲むインスタンスは,Primary 式の値のオブジェクトとする。
- もしクラスインスタンス生成式が,非限定クラスインスタンス生成式ならば,
15.9.3 コンストラクタと引数の選択
C はインスタンス化されたクラス型と仮定する。 C,i のインスタンスを生成するために,C のコンストラクタはコンパイル時に次の規則によって選択される。
- 最初に,コンストラクタ呼出しの実際の実引数が決定される。
- もし C が匿名クラスであり,及び C と内部クラス S の直接的上位クラスであるならば,
- もし S が局所クラスであり及び S が静的文脈の中で現れるならば,実引数リストの中の引数がもし存在すれば,その式に現れる順序でコンストラクタへの引数とする。
- そうでなければ,S に関しては i の直接的に取り囲むインスタンスは,コンストラクタへの最初の実引数であり,その後にそのクラスインスタンス生成式の実引数リストがもし存在すれば,その式の中に現れる順序で実引数が現れる。
- そうでなければ,その実引数リストの引数がもし存在すれば,それがその式の中に現れる順序で,そのコンストラクタの実引数とする。
- もし C が匿名クラスであり,及び C と内部クラス S の直接的上位クラスであるならば,
- 一旦その実引数リストが決定されると,メソッド呼出し(15.12)に関する同じ規則を使用して,それらは C のコンストラクタを選択するために使用される。 メソッド呼び出し中に,もし適用可能及びアクセス可能な一意な最も固有のコンストラクタが存在しないならば,コンパイル時メソッド照合エラーが発生する。
15.9.4 クラスインスタンス生成式の実行時評価
実行時には,クラスインスタンス生成式の評価は次のようになる。
最初に,もしクラスインスタンス生成式が限定クラスインスタンス生成式であるならば,その限定する基本式が評価される。
もしその限定する式を評価したら null になるならば,NullPointerException が投げられ,及びそのクラスインスタンス生成式は中途完了する。
もしその限定する式が中途完了するならば,そのクラスインスタンス生成式は同じ理由で中途完了する。
次に,新しいクラスインスタンスのためにスペースが割り当てられる。
もしオブジェクトを割り当てるためのスペースが不十分ならば,そのクラスインスタンス生成式の評価は,OutOfMemoryError (15.9.6)を投げて,中途完了する。
その新しいオブジェクトは,その規定されたクラス型とそのすべての上位クラスで宣言されるすべてのフィールドの新しいインスタンスを含む。 新しいフィールドインスタンスが生成されるときは,そのデフォルト値(4.5.5)に初期化される。
次に,そのコンストラクタに対する実引数が,左から右に評価される。 もし実引数評価のいずれかが中途完了するならば,その右側の実引数式は評価されず,及びクラスインスタンス生成式も同じ理由で中途完了する。
次に,その規定されたクラス型の選択されたコンストラクタが呼び出される。 これは,そのクラス型の各上位クラスに対して少なくとも一つのコンストラクタを呼び出す。 この過程は明示的なコンストラクタ呼出し文(8.6)によって指示でき,及び12.5で詳細に示す。
クラスインスタンス生成式の値は,その規定されたクラスの新しく作り出されたオブジェクトへの参照とする。 式が評価される毎に,新しいオブジェクトが生成される。
15.9.5 匿名クラス宣言
匿名クラス宣言は,コンパイラによって,クラスインスタンス生成式から自動的に導き出される。
匿名クラスは,abstract (8.1.1.1)では決してない。
匿名クラスは,常に内部クラス(8.1.2)であるが,static (8.1.1, 8.5.2)では決してない。
匿名クラスは,常に暗黙の final (8.1.1.2)とする。
15.9.5.1 匿名コンストラクタ
匿名クラスは,明示的に宣言されたコンストラクタをもつことはできない。 その代りに,コンパイラはその匿名クラスのために自動的に 匿名コンストラクタ を用意しなければならない。 直接的上位クラス S をもつ匿名クラス C の匿名コンストラクタの形式は,次に従う。
- もし S が内部クラスでない又は S が静的文脈の中に現れる局所クラスである場合,匿名コンストラクタは C が宣言されたクラスインスタンス生成式のそれぞれの実引数に対して一つの仮引数をもつ。
クラスインスタンス生成式の実引数は,メソッド呼出し(15.12)に関する同じ規則を使用して,S のコンストラクタ cs を決定するために使用される。
その匿名コンストラクタのそれぞれの実引数の型は,それに対応する cs の実引数と同一でなければならない。
コンストラクタの本体は,
super(...)の形式の明示的なコンストラクタ呼出し(8.8.5.1)から成り,その実引数はコンストラクタの実引数であり,それが宣言された順序とする。 - そうでなければ,C のコンストラクタの最初の実引数は,S に関して i の直接的に取り囲むインスタンスの値を表す。
この仮引数の型は,S の宣言を直接的に含むクラス型とする。
そのコンストラクタは,匿名クラスを宣言するクラスインスタンス生成式のそれぞれの実引数に対して追加の実引数をもつ。
その n 番目の実引数 e は,n-1番目の実引数に対応する。
そのクラスインスタンス生成式の実引数は,メソッド呼出し(15.12)に関する同じ規則を使用して,S のコンストラクタ cs を決定するために使用される。
その匿名コンストラクタのそれぞれの実引数の型は,cs の対応する実引数と同じでなければならない。
そのコンストラクタの本体は,o.
super(...)の形式の明示的なコンストラクタ呼出し(8.8.5.1)から成り,及びその実引数はコンストラクタの後に続く実引数であり,それが宣言された順序とする。
その匿名クラスのシグネチャは,アクセス不可能型(例えば,もしそのような型が cs の上位クラスコンストラクタのシグネチャに現れる場合)を参照できることに注意すること。 これは,それ自身は,コンパイル時又は実行時のどちらかでエラーを起こさない。
15.9.6 例: 評価順序及びメモリ不足の検出
もしクラスインスタンス生成式の評価で生成操作の実行にメモリが不十分なことがわかれば,OutOfMemoryError が投げられる。
この検査は実引数式を評価する前に行う。
class List {
int value;
List next;
static List head = new List(0);
List(int n) { value = n; next = head; head = this; }
}
class Test {
public static void main(String[] args) {
int id = 0, oldid = 0;
try {
for (;;) {
++id;
new List(oldid = id);
}
} catch (Error e) {
System.out.println(e + ", " + (oldid==id));
}
}
}
なぜなら,その実引数式java.lang.OutOfMemoryError: List, false
oldid = id が評価される前に,メモリ不足条件が検出されたからである。これを,次元式(15.10.3)を評価した後にメモリ不足状態が検出された場合に対する配列生成式(15.10)の処理と比較すること。
15.10 配列生成式
配列インスタンス生成式は,新しい配列(10.)を生成するために使用される。
ArrayCreationExpression: new PrimitiveType DimExprs Dimsopt new TypeName DimExprs Dimsopt new PrimitiveType Dims ArrayInitializer new TypeName Dims ArrayInitializer
DimExprs: DimExpr DimExprs DimExpr DimExpr: [ Expression ] Dims: [ ] Dims [ ]配列生成式は,要素が PrimitiveType 又は TypeName によって規定された型である新しい配列であるオブジェクトを生成する。 TypeName は,
abstract クラス型(8.1.1.1)又はインタフェース型(9.)さえも含む,どのような名前付き参照型を指定してもよい。
その生成式の型は,new キーワード,任意の DimExpr 式及び配列初期化子が削除されたその生成式の複写によって指示されうる配列型とする。
例えば,次の生成式の型は,
次の通りとする。new double[3][3][]
DimExpr の中のそれぞれの次元式の型は整数型でなければならず,そうでなければコンパイル時エラーが発生する。 それぞれの式は,単項数値昇格(5.6.1)を受ける。 その昇格型はdouble[][][]
int でなければならず,そうでなければコンパイル時エラーが発生する。
特に,これは次元式の型は long であってはならないことを意味する。もし配列初期化子が用意されているならば,10.6で示すように,新しく割り当てられた配列は配列初期化子によって用意された値で初期化される。
15.10.1 配列生成式の実行時評価
実行時に,配列生成式の評価は次のように実行される。 もし次元式がないならば,配列初期化子が存在しなければならない。 その配列初期化子の値は,配列生成式の値とする。 そうでなければ,次のように評価される。最初に次元式が左から右に評価される。 もし式の評価が中途完了するならば,その右の式は評価されない。
次に次元式の値が検査される。
もし DimExpr 式の値がゼロより小さければ,NegativeArraySizeException が投げられる。
次にスペースが新しい配列に割り当てられる。
もしその配列を割り当てるためのスペースが不足しているならば,OutOfMemoryError を投げて,配列生成式の評価は中途完了する。
もし単一の DimExpr が現れるならば,一次元配列がその規定された長さで生成されて,及び配列の各構成要素はそのデフォルト値(4.5.5)に初期化される。
もし配列生成式が N 個の DimExpr 式を含むならば,それは配列の含まれた配列を生成するために,深さ N-1の入れ子のループの組を実行する。
動作においては次に等しい。float[][] matrix = new float[3][3];
及び,float[][] matrix = new float[3][]; for (int d = 0; d < matrix.length; d++) matrix[d] = new float[3];
は次に等しい。Age[][][][][] Aquarius = new Age[6][10][8][12][];
Age[][][][][] Aquarius = new Age[6][][][][];
for (int d1 = 0; d1 < Aquarius.length; d1++) {
Aquarius[d1] = new Age[10][][][];
for (int d2 = 0; d2 < Aquarius[d1].length; d2++) {
Aquarius[d1][d2] = new Age[8][][];
for (int d3 = 0; d3 < Aquarius[d1][d2].length; d3++) {
Aquarius[d1][d2][d3] = new Age[12][];
}
}
}
new 式は,実際に長さ6の一つの配列,長さ10の六つの配列,長さ8の6 x 10 = 60の配列及び長さ12の6 x 10 x 8 = 480の配列を生成する。
この例では,5番目の次元が残されており,これは空参照だけに初期化された実際の配列要素(Age オブジェクトへの参照)を含む配列とする。
これらの配列は,後で次のような別のコードで代入することができる。
Age[] Hair = { new Age("quartz"), new Age("topaz") };
Aquarius[1][9][6][9] = Hair;
float triang[][] = new float[100][]; for (int i = 0; i < triang.length; i++) triang[i] = new float[i+1];
15.10.2 例: 配列生成評価順序
配列生成式(15.10)の中には,それぞれの括弧の中に一つ以上の次元式があってもよい。 それぞれの次元式は,その右の次元式の前に完全に評価される。
class Test {
public static void main(String[] args) {
int i = 4;
int ia[][] = new int[i][i=3];
System.out.println(
"[" + ia.length + "," + ia[0].length + "]");
}
}
なぜなら,2番目の次元式が[4,3]
i に 3 を代入する前に,最初の次元が計算されて 4 になるからである。もし,次元式の評価が中途完了するならば,その右に現れる次元式の部分は一切評価されない。 したがって,次の例は,
class Test {
public static void main(String[] args) {
int[][] a = { { 00, 01 }, { 10, 11 } };
int i = 99;
try {
a[val()][i = 1]++;
} catch (Exception e) {
System.out.println(e + ", i=" + i);
}
}
static int val() throws Exception {
throw new Exception("unimplemented");
}
}
なぜならjava.lang.Exception: unimplemented, i=99
i に 1 を代入する代入式は決して実行されないからである。15.10.3 例: 配列生成及びメモリ不足の検出
もし配列生成式の評価で生成操作を実行するためにメモリが不十分であることを検出するならば,OutOfMemoryError が投げられる。
この検査は,すべての次元式の評価が正常完了した後にだけ起こる。
class Test {
public static void main(String[] args) {
int len = 0, oldlen = 0;
Object[] a = new Object[0];
try {
for (;;) {
++len;
Object[] temp = new Object[oldlen = len];
temp[0] = a;
a = temp;
}
} catch (Error e) {
System.out.println(e + ", " + (oldlen==len));
}
}
}
なぜなら,その次元式のjava.lang.OutOfMemoryError, true
oldlen = len が評価された後に,メモリ不足状態が検出されるからである。これと,実引数式(15.9.6)を評価する前に,メモリ不足状態を検出するクラスインスタンス生成式(15.9)を比較すること。
15.11 フィールドアクセス式
フィールドアクセス式は,オブジェクト又は配列のフィールドにアクセスでき,式又は特別なキーワードsuper のどちらかの値への参照とする
(単純名を使用して現在のインスタンス又はクラスのフィールドを参照することもできる。
6.5.6を参照すること。)。
FieldAccess: Primary . Identifier super . Identifier ClassName . super . Identifierフィールドアクセス式の意味は,限定名(6.6)と同じ規則を使用して決定されるが,式がパッケージ,クラス型又はインタフェース型を指示することができないという制限がある。
15.11.1 一次式によるフィールドアクセス
Primary の型は参照型 T でなければならず,そうでなければコンパイル時エラーが発生する。 そのフィールドアクセス式の意味は,次のように決定される。
- もしその識別子が,型 T の複数のアクセス可能メンバフィールドの名前を指すなら,そのフィールドアクセスはあいまいであり,及びコンパイル時エラーが発生する。
- もしその識別子が,型 T のアクセス可能メンバフィールドを指さないなら,そのフィールドアクセスは未定義であり,及びコンパイル時エラーが発生する。
- そうでなければ,その識別子は,型Tの単一のアクセス可能メンバフィールドを指して,そのフィールドアクセス式の型はフィールドの宣言型とする。 実行時に,そのフィールドアクセス式の結果は次のように計算される。
class S { int x = 0; }
class T extends S { int x = 1; }
class Test {
public static void main(String[] args) {
T t = new T();
System.out.println("t.x=" + t.x + when("t", t));
S s = new S();
System.out.println("s.x=" + s.x + when("s", s));
s = t;
System.out.println("s.x=" + s.x + when("s", s));
}
static String when(String name, Object t) {
return " when " + name + " holds a "
+ t.getClass() + " at run time.";
}
}
この最終行は,実際にはアクセスされるフィールドは,その被参照オブジェクトの実行時のクラスに依存しないことを示す。t.x=1 when t holds a class T at run time. s.x=0 when s holds a class S at run time. s.x=0 when s holds a class T at run time.
s がクラス T のオブジェクトに対する参照を持っていたとしても,その式 s.x はクラス S のフィールド x を参照する。なぜなら,式 s の型が S だからである。
クラス T のオブジェクトは,x と命名された二つのフィールドを含む。
一つはクラス T に対してであり,もう一つはその上位クラス S に対してとする。フィールドアクセスのために動的に検索しないので,簡単な実装でもプログラムは効率良く実行される。 遅延束縛と上書きの機能を利用できるが,インスタンスメソッドが使用されるときに限られる。 そのフィールドにアクセスするインスタンスメソッドを使用した次の同じ例について考える。
class S { int x = 0; int z() { return x; } }
class T extends S { int x = 1; int z() { return x; } }
class Test {
public static void main(String[] args) {
T t = new T();
System.out.println("t.z()=" + t.z() + when("t", t));
S s = new S();
System.out.println("s.z()=" + s.z() + when("s", s));
s = t;
System.out.println("s.z()=" + s.z() + when("s", s));
}
static String when(String name, Object t) {
return " when " + name + " holds a "
+ t.getClass() + " at run time.";
}
}
この最終行は,実際にはアクセスされるメソッドが被参照オブジェクトの実行時クラスに依存することを示す。t.z()=1 when t holds a class T at run time. s.z()=0 when s holds a class S at run time. s.z()=1 when s holds a class T at run time.
s がクラス T のオブジェクトに対する参照を持っているとき,その式 s.z() は,s の型が S であるにもかかわらず,クラス T のメソッド z を参照する。
クラス T のメソッド z は,クラス S のメソッド z を上書きする。
次の例は,例外を引き起こさずに,クラス(static)変数にアクセスするために空参照が使用される例を示す。
class Test {
static String mountain = "Chocorua";
static Test favorite(){
System.out.print("Mount ");
return null;
}
public static void main(String[] args) {
System.out.println(favorite().mountain);
}
}
Mount Chocorua
favorite() の結果が null であるにもかかわらず,NullPointerException は投げられない。
その表示される"Mount"は,その値でなく型だけがアクセスするフィールドの決定に使用されたにもかかわらず,実際には Primary 式が完全に評価されたことを示している(なぜなら,そのフィールド mountain が static だからである。)。
15.11.2 super による上位クラスメンバのアクセス
キーワード super を使用する特別な形式は,インスタンスメソッド,コンストラクタ又はクラスのインスタンス変数の初期化子の中でだけ有効とする。
これはキーワード this を使用してよい状況とまったく同じ状況である(15.8.3)。
クラス Object は上位クラスを持たないので,super を含む形式は Object では使用してはいけない。
もし super がクラス Object に現れるならば,コンパイル時エラーが発生する。
フィールドアクセス式 super.name がクラス C の中に現れ,及び C の直接的上位クラスがクラス S であると仮定する。
それならば super.name は,まさにそれが式 ((S)this).name のように扱われる。
したがって,それは現在のオブジェクトの name という名前のフィールドを参照するが,しかし現在のオブジェクトは上位クラスのインスタンスとして見られる。
したがって,たとえそのフィールドがクラス C の中の name というフィールド宣言によって隠ぺいされたとしても,クラス S で見える name という名前のフィールドにアクセスできる。
interface I { int x = 0; }
class T1 implements I { int x = 1; }
class T2 extends T1 { int x = 2; }
class T3 extends T2 {
int x = 3;
void test() {
System.out.println("x=\t\t"+x);
System.out.println("super.x=\t\t"+super.x);
System.out.println("((T2)this).x=\t"+((T2)this).x);
System.out.println("((T1)this).x=\t"+((T1)this).x);
System.out.println("((I)this).x=\t"+((I)this).x);
}
}
class Test {
public static void main(String[] args) {
new T3().test();
}
}
クラスx= 3 super.x= 2 ((T2)this).x= 2 ((T1)this).x= 1 ((I)this).x= 0
T3 の中では,その式 super.x はまさに次のようであるかのように扱われる。
フィールドアクセス式((T2)this).x
T.super.name がクラス C の中に現れ,及び T が指示するクラスの直接の上位クラスは全限定名が S であるクラスであると仮定する。
それならば,T.super.name は,それが式((S)T.this).name であるかのように厳密に処理される。
したがって,式 T.super.name は,S という名前のクラスの中で見ることができる name という名前のフィールドに,そのフィールドが T という名前のクラスの中で name という名前のフィールドを宣言することで隠ぺいされた場合でさえも,アクセスできる。
もし Tが指示するクラスがその現在のクラスの字句的に取り囲むクラスでない場合には,コンパイル時エラーが発生する。
15.12 メソッド呼出し式
メソッド呼出し式は,クラス又はインスタンスメソッドを呼出すために使用される。
MethodInvocation: MethodName ( ArgumentListopt ) Primary . Identifier ( ArgumentListopt ) super . Identifier ( ArgumentListopt ) ClassName . super . Identifier ( ArgumentListopt )便宜上,15.9のArgumentList の定義を繰り返す。
ArgumentList: Expression ArgumentList , Expressionコンパイル時のメソッド名の解決は,メソッドオーバロードの可能性のため,フィールド名の解決より複雑になる。 実行時のメソッドの呼出しもまた,インスタンスメソッドの上書きの可能性のため,フィールドの参照より複雑になる。
あるメソッド呼出し式により呼び出されるメソッドの決定は,幾つかの段階を含む。 次の三つの章は,メソッド呼出しのコンパイル時の処理を示す。 さらにメソッド呼出し式の型の決定は,15.12.3で示す。
15.12.1 コンパイル時ステップ 1: 探索すべきクラス又はインタフェースの決定
コンパイル時のメソッド呼出し処理の最初の段階は,呼び出すメソッドの名前と,その名前のメソッドの定義を調べるクラス又はインタフェースを明らかにする。 次のとおり,左括弧に先行する形式に応じて,幾つかの考慮すべき場合がある。
- もしその形式が MethodName ならば,さらに三つの場合がある。
- もしそれが単純名,すなわち Identifier ならば,そのメソッドの名前はその Identifier とする。 もしその Identifier がその名前で見えるメソッド宣言の有効範囲(6.3)内に現れるならば,そのメソッドがメンバである取囲み型宣言でなければならない。 T が最内部のそのような型宣言だと仮定すると,検索されるクラス又はインタフェースは T とする。
- もしそれが TypeName
.Identifier という形式の限定名ならば,メソッドの名前はその Identifier であり,及び検索するクラスは,その TypeName で命名されたものとする。 もし TypeName がクラスではなくインタフェースの名前ならば,コンパイル時エラーが発生する。 なぜなら,この形式はstaticメソッドだけを呼び出せるが,インタフェースはstaticメソッドを持たないからである。 - 他のすべての場合,その限定名は FieldName
.Identifier という形式であり,そのメソッドの名前はその Identifier であり,及び検索するクラス又はインタフェースは,FieldName によって命名されたフィールドの宣言された型とする。
- もしその形式が Primary
.Identifier であるならば,そのメソッドの名前はその Identifier であり,及び検索されるクラス又はインタフェースは,その Primary の型とする。 - もしその形式が
super.Identifier であるならば,メソッドの名前は Identifier であり,及び検索されるクラスは,その宣言がそのメソッド呼出しを含むクラスの上位クラスとする。 T がメソッド呼出しを直接的に含む型宣言だと仮定すると,次のような状況のいずれかが発生する場合に,コンパイル時エラーになる。 - もしその形式が ClassName
.super.Identifier であるならば,そのメソッドの名前は Identifier であり,及び検索されるクラスは ClassName で指示されるクラス C の上位クラスとする。 もし C が現在のクラスの字句的に取り囲むクラスでないならば,コンパイル時エラーが発生する。 もし C がクラスObjectであるなら,コンパイル時エラーが発生する。 もし次のような状況のいずれかであるならば,コンパイル時エラーが発生する。
15.12.2 コンパイル時ステップ 2: メソッドシグネチャの決定
2番目の段階は,メソッド呼出しのために前の段階において決定されたクラス又はインタフェースを検索する。 この段階は,適用可能 (applicable) 及び参照可能 (accessible) なメソッド宣言,すなわち,その与えられた実引数で正しく呼び出されることができる宣言を配置するために,そのメソッドの名前及び実引数式の型を使用する。 そのときには最も特殊 (most specific) なものが選択される場合は,そのようなメソッド宣言が複数存在してよい。 最も特殊なメソッド宣言の記述子(シグネチャと返却値の型)は,実行時にメソッドディスパッチを行うために使用される。15.12.2.1 適用可能及び参照可能なメソッドの探索
メソッド宣言は,次の二つが成り立つ場合に限り,メソッド呼出しに対して 適用可能 (applicable) とする。
- メソッド宣言の中の仮引数の数が,そのメソッド呼出しの中の実引数式の数に等しい。
- それぞれの実引数の型は,メソッド呼出し変換(5.3)によって対応する仮引数の型に変換可能とする。
メソッド呼出し変換は,型
intの定数が,決して暗黙のうちにbyte,short又はcharに縮小されないということを除いて,代入変換(5.2)と同じとする。
メソッド宣言がメソッド呼出しから参照可能 (accessible) (6.6)かどうかは,そのメソッド宣言のアクセス修飾子(public,なし,protected 又は private )及びメソッド呼出しの現れる場所に依存する。
もしクラス又はインタフェースが適用可能及び参照可能なメソッド宣言を持たないならば,コンパイル時エラーが発生する。
public class Doubler {
static int two() { return two(1); }
private static int two(int i) { return 2*i; }
}
class Test extends Doubler {
public static long two(long j) {return j+j; }
public static void main(String[] args) {
System.out.println(two(3));
System.out.println(Doubler.two(3)); // compile-time error
}
}
Doubler 内のメソッド呼出し two(1) に対し,two と命名された二つの参照可能なメソッドがあるが,2番目だけが適用可能であり,したがってそれが実行時に呼び出される。
クラス Test 内のメソッド呼出し two(3) に対しては二つの適用可能なメソッドがあるが,クラス Test 内のものだけがアクセス可能であり,したがって実行時に呼び出される(その実引数3は型 long に変換される。)。
メソッド呼出し Doubler.two(3) に対しては,クラス Test ではなくクラス Doubler が,two と命名されたメソッドのために検索される。
しかし,唯一の適用可能なメソッドがアクセス可能ではないので,このメソッド呼出しはコンパイル時エラーを発生する。
class ColoredPoint {
int x, y;
byte color;
void setColor(byte color) { this.color = color; }
}
class Test {
public static void main(String[] args) {
ColoredPoint cp = new ColoredPoint();
byte color = 37;
cp.setColor(color);
cp.setColor(37); // compile-time error
}
}
setColor の2番目の呼出しでコンパイル時エラーが発生する。
リテラル 37 の型は int であり,メソッド呼出し変換では int は byte 型に変換できない。
その変数 color の初期化で使用される代入変換は,int 型から byte 型へ定数の暗黙の変換を実行する。
なぜなら,その値 37 は byte 型で表すのに十分小さいから許されている。
しかし,メソッド呼出し変換ではそのような変換は認められない。
しかし,もしメソッド setColor が byte の代わりに int をとるように宣言されていたならば,メソッド呼出しは両方とも正しい。
つまり,最初の呼出しはメソッド呼出し変換が byte から int へ拡張する変換を許すために可能とする。
しかし,縮小キャストが setColor の本体には必要とする。
void setColor(int color) { this.color = (byte)color; }
15.12.2.2 最も特殊なメソッドの選択
もし複数のメソッドがメソッド呼出しに対してアクセス可能及び適用可能ならば,実行時メソッドディスパッチのための記述子にその内の一つを与える必要がある。 Javaプログラム言語は,最も特殊な (most specific) メソッドを選ぶという規則を用いている。非公式な直観としては,もし最初のメソッドによって処理されるあらゆる呼出しがコンパイル時型エラーなしに他に渡されることができるならば,そのメソッド宣言はより特殊とする。
正確な定義を次に示す。 m を名前とすると,m と命名された二つのメソッド宣言があり,それぞれが n 個の仮引数をもつと仮定する。 もし一つの宣言がクラス又はインタフェース T 内に現れ,その仮引数の型は T1, . . . , Tn であり,さらにもう一方の宣言がクラス又はインタフェース U 内に現れ,その仮引数の型は U1,. . . , Un とする。 それならば,次が共に成り立つ時に限り,T の中で宣言されたメソッド m は,U の中で宣言されたメソッド m よりも特殊 (more specific)とする。
もしメソッドが適用可能かつアクセス可能で,その他には,より特殊で適用可能及びアクセス可能なメソッドがないならば,最大限に特殊 (maximally specific) であると呼ばれる。
もしちょうど一個の最大限に特殊なメソッドがあるならば,それは実際に 最も特殊 (the most specific)なメソッドとする。 それは必然的に,適用可能でアクセス可能な他のどのメソッドよりも特殊とする。 したがって,それは15.12.3で示されたように,さらにコンパイル時の検査が必要とする。
二つ又はそれ以上の最大限に特殊なメソッド宣言があるために,どのメソッドも最も特殊ではないことがある。 この場合を,次に示す。
- もしすべての最大限に特殊なメソッドが同じシグネチャをもたないならば,
- もし,その最大限に特殊なメソッドの一つが
abstractを宣言しないのならば,それは最も特殊なメソッドとする。 - そうでなければ,すべての最大限に特殊なメソッドは必然的に
abstractを宣言する。 最も特殊なメソッドは,その最大限に特殊なメソッドの中から勝手に選択される。 しかし,その最も特殊なメソッドは,検査例外がそれぞれの最大限に特殊なメソッドのthrows節の中で宣言された場合に限り,その例外を投げると考えられる。
- もし,その最大限に特殊なメソッドの一つが
- そうでなければ,そのメソッド呼出しはあいまいであるとよび,及びコンパイル時エラーが発生する。
15.12.2.3 例: オーバロードのあいまいさ
次の例について考える。
class Point { int x, y; }
class ColoredPoint extends Point { int color; }
class Test {
static void test(ColoredPoint p, Point q) {
System.out.println("(ColoredPoint, Point)");
}
static void test(Point p, ColoredPoint q) {
System.out.println("(Point, ColoredPoint)");
}
public static void main(String[] args) {
ColoredPoint cp = new ColoredPoint();
test(cp, cp); // compile-time error
}
}
test の二つの宣言があり,どちらも他方より特殊ではないことである。
それゆえ,このメソッド呼出しはあいまいとする。
static void test(ColoredPoint p, ColoredPoint q) {
System.out.println("(ColoredPoint, ColoredPoint)");
}
15.12.2.4 例: 返却値の型の無視
別の例として,次を考える。
class Point { int x, y; }
class ColoredPoint extends Point { int color; }
class Test {
static int test(ColoredPoint p) {
return p.color;
}
static String test(Point p) {
return "Point";
}
public static void main(String[] args) {
ColoredPoint cp = new ColoredPoint();
String s = test(cp); // compile-time error
}
}
test の最も特殊な宣言は,型 ColoredPoint を仮引数にとるものとする。
メソッドの返却値の型は int であり,int は割り当て変換によって String には変換できないためにコンパイル時エラーが発生する。
この例は,メソッドの返却値の型はオーバロードされたメソッドの解決には関与しないことを示す。
String を返却する2番目の test メソッドは,この例のプログラムをエラーなしにコンパイルできるようにする返却値の型をもつ場合でさえも,選択されない。15.12.2.5 例: コンパイル時の解決
コンパイル時に,最も適用可能なメソッドが選ばれる。 その記述子は,実行時にどのメソッドが実際に実行されるかを決定する。 もし新しいメソッドがクラスに追加されるならば,たとえ再コンパイルすれば新たなメソッドが選ばれるようになるとしても,そのクラスの古い定義でコンパイルされたソースコードはその新しいメソッドを使用しない。
例として,二つのコンパイル単位を考える。一つは クラスPoint とし,
package points;
public class Point {
public int x, y;
public Point(int x, int y) { this.x = x; this.y = y; }
public String toString() { return toString(""); }
public String toString(String s) {
return "(" + x + "," + y + s + ")";
}
}
ColoredPointとする。
package points;
public class ColoredPoint extends Point {
public static final int
RED = 0, GREEN = 1, BLUE = 2;
public static String[] COLORS =
{ "red", "green", "blue" };
public byte color;
public ColoredPoint(int x, int y, int color) {
super(x, y); this.color = (byte)color;
}
/** Copy all relevant fields of the argument into
this ColoredPoint object. */
public void adopt(Point p) { x = p.x; y = p.y; }
public String toString() {
String s = "," + COLORS[color];
return super.toString(s);
}
}
ColoredPoint を用いる3番目のコンパイル単位を考える。
import points.*;
class Test {
public static void main(String[] args) {
ColoredPoint cp =
new ColoredPoint(6, 6, ColoredPoint.RED);
ColoredPoint cp2 =
new ColoredPoint(3, 3, ColoredPoint.GREEN);
cp.adopt(cp2);
System.out.println("cp: " + cp);
}
}
クラスcp: (3,3,red)
Test を実装したアプリケーションプログラマは,単語 green を期待していた。
なぜなら,実引数 ColoredPoint は color フィールドを持ち,color は"適切なフィールド"のように見えるからである(もちろん,パッケージ Points に対するドキュメントはもっと正確であるべきとする。)。
ところで,adopt のメソッド呼出しのために最も特殊なメソッド(実際には,唯一の適用可能なメソッド)は一個の仮引数のメソッドを示すシグネチャを持ち,その仮引数は Point 型であることに注意すること。
このシグネチャは,コンパイラにより生成される Test クラスのバイナリ表現の一部となり,実行時にメソッド呼出しに使用される。
プログラマがこのソフトウェアエラーを報告し,points パッケージの管理者が,相応の考慮の後,クラス ColoredPoint に次のメソッドを追加することにより訂正することを決めたと仮定する。
public void adopt(ColoredPoint p) {
adopt((Point)p); color = p.color;
}
Test の古いバイナリファイルを ColoredPoint の新しいバイナリファイルとともに実行するならば,出力は次のように変化しない。
なぜならcp: (3,3,red)
Test の古いバイナリファイルが,メソッド呼出し cp.adopt(cp2) に関係する"仮引数一個,型は Point; void"という記述子をまだ持っているからである。
もし Test のソースコードを再コンパイルするならば,コンパイラが今度は二つの適用可能な adopt メソッドがあり,最も特殊なメソッドのシグネチャが"仮引数一個,型は ColoredPoint; void"であることを発見する。
プログラムを実行すると,今度は望ましい出力を生成する。
この問題についてよく考えると,cp: (3,3,green)
points パッケージの管理者は,ColoredPoint クラスを,まだ ColoredPoint の実引数で起動される古いコードのために古い adopt メソッドに防御的なコードを追加することにより,新たにコンパイルされたコードと古いコードの両方で動作するように修正することができる。
public void adopt(Point p) {
if (p instanceof ColoredPoint)
color = ((ColoredPoint)p).color;
x = p.x; y = p.y;
}
15.12.3 コンパイル時ステップ3: 選ばれたメソッドの適切性
もしメソッド呼出しのための最も特殊なメソッド宣言があるならば,それはそのメソッド呼出しのためのコンパイル時宣言 (compile-time declaration) と呼ばれる。 コンパイル時宣言においては,さらに次の三つの検査を行わねばならない。
- もしメソッド呼出しが左括弧の前に Identifier の形式の MethodName を持ち,及びそのメソッドがインスタンスメソッドであるならば,
- もしその呼出しが静的文脈(8.1.2)内に現れるならば,コンパイル時エラーが発生する
(この理由は,この形式のメソッド呼出しは,
this(15.8.3)が定義されない場所で,インスタンスメソッドを呼び出すために使用できないからである。)。 - さもなければ,C がそのメソッドがメンバである最内部取囲みクラスでなければならないと仮定する。 もしその呼出しが C 又は C の内部クラスによって直接囲まれていないならば,コンパイル時エラーが発生する。
- もしその呼出しが静的文脈(8.1.2)内に現れるならば,コンパイル時エラーが発生する
(この理由は,この形式のメソッド呼出しは,
- もしメソッド呼出しが左括弧の前に
TypeName.Identifier の形式の MethodName をもつならば,そのコンパイル時宣言はstaticでなければならない。 もし,そのメソッド呼出しがインスタンスメソッドに対するものであるならば,コンパイル時エラーが発生する (この理由は,この形式のメソッド呼出しはインスタンスメソッド内でthisとして機能するオブジェクトへの参照を指定できないからである)。 - もしそのメソッド呼出しが左括弧の前に
super. Identifier 形式の MethodName をもつ場合には, - もしそのメソッド呼出しが左括弧の前に ClassName.
super. Identifier 形式の MethodName をもつならば,- もしそのメソッドが
abstractであるならば,コンパイル時エラーが発生する。 - もしそのメソッド呼出しが静的文脈内でおこなわれるならば,コンパイル時エラーが発生する。
- そうでなければ,C が ClassName によって指示されるクラスだと仮定する。 その呼出しが C 又は C の内部クラスによって直接取り囲まれていない場合,コンパイル時エラーが発生する。
- もしそのメソッドが
- もしそのメソッド呼出しに対するコンパイル時宣言が
voidならば,メソッド呼出しは最上位の式でなければならない。 つまり,式文(14.8)又はfor文(14.13)の ForInit 又は ForUpdate 部分の中の Expression であるか,又はコンパイル時エラーが発生する (その理由は,そのようなメソッド呼出しは値を返さないので,値が必要でない場合にだけ使用されるべきであるからである。)。
- そのメソッドの名前。
- そのメソッド呼出しの限定型(13.1)。
- 順序付きの仮引数の数と型
- コンパイル時宣言の中で宣言される返却値の型又は
void。 - 呼出しのモード。これは次のように計算される。
- もしコンパイル時宣言が
static修飾子を含むならば,呼出しのモードはstaticとする。 - そうでなければ,もしコンパイル時宣言がprivate修飾子を含むならば,呼出しのモードは
nonvirtualとする。 - そうでなければ,もし左括弧の前のメソッド呼出しの部分が
super.Identifier の形又は ClassName.super.Identifier の形式であるならば,呼出しのモードはsuperとする。 - そうでなければ,もしコンパイル時宣言がインタフェース内にあるならば,呼出しのモードは
interfaceとする。 - そうでなければ,呼出しのモードは
virtualとする。
- もしコンパイル時宣言が
void でないならば,そのメソッド呼出しの式の型はコンパイル時宣言で規定される返却値の型とする。15.12.4 メソッド呼出しの実行時評価
実行時に,メソッド呼出しは五つの段階を必要とする。 最初に,ターゲットへの参照 (target reference) を計算してよい。 2番目に,その引数式が評価される。 3番目に,呼び出されるメソッドのアクセス可能性が検査される。 4番目に,メソッドが実行される実際のコードを探す。 5番目に,新しい活性化フレームが作成され,必要なら同期処理が実行され,制御がメソッドコードに移される。15.12.4.1 ターゲット参照の計算(必要な場合)
MethodInvocation (15.12)の四つの生成規則のどれに関係するのかによって,幾つかの考えられる事例が存在する。
- もし MethodName を含む MethodInvocation の最初の生成規則が適用するならば,さらに次の三つの事例がある。
- もし MethodName が単純名,すなわち Identifier であるならば,さらに次の二つの事例がある。
- もし呼出しのモードが
staticであるならば,ターゲットへの参照はない。 - そうでなければ,T がそのメソッドがメンバである取囲み型宣言であり,T が
thisの n 番目の字句的に取り囲む型宣言(8.1.2)であるように,n が整数であると仮定する。 したがって,そのターゲットの参照は,thisの n 番目の字句的に取り囲むインスタンス(8.1.2)とする。 もしthisの n 番目の字句的に取り囲むインスタンス(8.1.2)が存在しなければ,コンパイル時エラーが発生する。
- もし呼出しのモードが
- もしその MethodName が TypeName.Identifier 形式の限定名であるならば,ターゲットへの参照はない。
- もしその MethodName が FieldNameIdentifier 形式の限定名であるならば,さらに次の二つの事例がある。
- もし MethodName が単純名,すなわち Identifier であるならば,さらに次の二つの事例がある。
- もし Primary を含む MethodInvocation の2番目の生成規則が適用されれば,さらに次の二つの事例がある。
- もしキーワード
superを含む MethodInvocation に3番目の生成規則が適用されるならば,そのターゲットへの参照はthisの値とする。 - もし ClassName.superの MethodInvocation に4番目の生成規則が適用されるならば,そのターゲットの参照は ClassName.thisの値とする。
15.12.4.2 実引数の評価
実引数は,左から右に順に評価される。 もしどれかの実引数式の評価が中途完了するならば,その右にある実引数の評価は行われず,同じ理由でそのメソッド呼出しも中途完了する。15.12.4.3 型及びメソッドのアクセス可能性の検査
C はメソッド呼出しを含むクラスであり,及び T はそのメソッド呼出しの限定型(13.1)であり,及び m はコンパイル時に定義されるそのメソッドの名前(15.12.3)だと仮定する。 Javaプログラム言語の実装は,そのメソッド m が型 T の中にまだ存在することを,リンクの一部として,保証しなければならない。 もしこれが真でないならば,NoSuchMethodError (これは IncompatibleClassChangeError の下位クラスである)が発生する。
もしその呼出しのモードが interface ならば,その実装はターゲットの参照型がその規定されたインタフェースを既に実装しているかについても検査しなければならない。
もしそのターゲットの参照型がまだインタフェースを実装していないならば,IncompatibleClassChangeError が発生する。その実装は,リンクの間に,その型 T 及びそのメソッド m がアクセス可能であることも保証しなければならない。 型 T に対しては,次の通りとする。
- もし T が C と同じパッケージの中にあれば,T はアクセス可能とする。
- もし T が C と異なるパッケージに存在し,及び T が
publicならば,T はアクセス可能とする。 - T が C と異なるパッケージに存在し,及び T が
protectedならば,T は C が T の下位クラスである場合に限り,アクセス可能とする。
- もし m が
publicであるならば,m はアクセス可能とする(インタフェースのすべてのメンバはpublicである(9.2)。)。 - もし m が
protectedであるならば,T が C と同一パッケージに属するか,又は C が T 又は T の下位クラスである場合に限り,mはアクセス可能とする。 - m がデフォルト(パッケージ)アクセスの場合,T が C と同じパッケージの中にある場合に限り,m はアクセス可能とする。
- m が
privateならば,C が T であるか,又はCがTを取り囲むか,又はTがCを取り囲むか,又はT及びCの両方が3番目のクラスに取り囲まれる場合に限り,m はアクセス可能とする。
IllegalAccessError が発生する(12.3)。 15.12.4.4 呼出しメソッドの検索
メソッド検索のための戦略は,呼出しのモードに依存する。
もし呼出しのモードが static であるならば,ターゲットの参照は必要なく,上書きも許されない。
クラス T のメソッド m が呼び出されるメソッドになる。
そうでなければ,インスタンスメソッドが呼び出され,ターゲットの参照が存在する。
もしターゲット参照が null であるならば,この時点で NullPointerException が投げられる。
そうでなければ,そのターゲットの参照は ターゲットオブジェクト (target object) を参照すると言い,及び呼び出されたメソッドで this キーワードの値として使用される。
呼出しのモードのための他の四つの可能性を検討する。
もし呼出しのモードが nonvirtual であるならば, 上書きは許されない。
クラス T のメソッド m が呼び出されるべきとする。
そうでなければ,呼出しのモードは interface,virtual 又は super のいずれかになり,上書きされるかもしれない。
その場合,動的なメソッド検索 (dynamic method lookup) が使用される。
動的な検索の過程はクラス S から開始され,次のように決定される。
- もし呼出しのモードが
interface又はvirtualであるならば,クラス S が初めにターゲットオブジェクトの実際の実行時クラス R となる。 これは,ターゲットオブジェクトが配列のインスタンスである場合でも正しい (呼出しのモードがinterfaceであれば, R は T を実装する必要があり,呼出しのモードがvirtualであれば,R は T 又は T の下位クラスである必要があることに注意すること)。 - もし呼出しのモードが
superであるならば,S は最初はメソッド呼出しの限定型(13.1)とする。
X が,そのメソッド呼出しのターゲット参照のコンパイル時型だと仮定する。
- もしクラス S がコンパイル時(15.12.3)に決定されるメソッド呼出しに必要なのと同じ(同じ数の仮引数,同じ仮引数型及び同じ返却値の型)記述子をもつ m という名前の非抽象メソッドの宣言を含むならば,
- もし呼出しモードが
super又はinterfaceであるならば,そのメソッドを呼び出し,手続きは終了する。 - もし呼出しモードが
virtualであり,及び S 内の宣言が X.m を上書き(8.4.6.1)するならば,S 内で宣言したメソッドが呼び出されるメソッドであり,手続きは終了する。
- もし呼出しモードが
- そうでなければ,もし S が上位クラスをもつならば,この同じ検索手順が S の代りに S の直接上位クラスを使用して再帰的に実行される。 呼び出されるメソッドは,この検索手順の再帰呼出しの結果とする。
ここで明示的に示した動的検索過程が,例えば,クラスごとのメソッドディスパッチ表の生成と使用又は効率的なディスパッチのために使用されるクラスごとの他のコンストラクタの生成の副作用として,しばしば暗黙的に実装されるということには注意を要する。
15.12.4.5 フレームの生成,同期及び制御の移行
あるクラス S のメソッド m が呼び出されると確認されたとする。
次に,新しい 活性化フレーム (activation frame) が作成される。
これは局所変数用の領域,呼び出されるメソッドが使用するスタック,その他すべての実装に必要な情報一覧(スタックポインタ,プログラムカウンタ,前の活性化フレームへの参照など)のための領域とともに,ターゲット参照(存在する場合)及び実引数値(存在する場合)を含む。
もし,そのような活性化フレームを生成するのに利用可能な十分なメモリがないならば,OutOfMemoryError が投げられる。
新しく作り出された活性化フレームは,現在の活性化フレームになる。
これにより,実引数値を新たに作り出された対応するメソッドの仮引数変数に割当てて,もし存在すれば this として利用可能なターゲット参照を作成する。
各実引数値がそれに対応する仮引数変数に割り当てられる前に,任意の要求された値集合変換(5.1.8)を含むメソッド呼出し変換(5.3)がおこなわれる。
もしそのメソッド m が native メソッドであり,必要なネイティブの実装依存なバイナリコードがロードされていない,又はそうでなくても動的にリンクすることができないならば,UnsatisfiedLinkError が投げられる。
もしそのメソッド m が synchronized 宣言されていないならば,制御は呼び出されるメソッド m の本体に移る。
もしそのメソッド m がsynchronized宣言されているならば,制御の移動の前にオブジェクトがロック設定されなければならない。
カレントスレッドがロックを獲得するまでは,それ以上処理を進めることはできない。
もしターゲット参照があるならば,ロック設定されなければならない。
そうでなければ,そのメソッド m が存在するクラス S のための Class オブジェクトがロック設定されなければならない。
そして,制御は呼び出されるメソッド m の本体に移される。
オブジェクトは正常完了,中途完了に関わらず,メソッド本体の実行が終了したとき,自動的にロック解除される。
ロック設定及びロック解除は,ちょうどそのメソッドの本体がsynchronized文(14.18)の中に埋め込まれているかのように振る舞う。
15.12.4.6 例: ターゲット参照及び静的メソッド
ターゲットの参照が計算され,及び呼出しのモードがstatic なのでそれが捨てられるとき,その参照が null であるかどうかは検査されない。
class Test {
static void mountain() {
System.out.println("Monadnock");
}
static Test favorite(){
System.out.print("Mount ");
return null;
}
public static void main(String[] args) {
favorite().mountain();
}
}
ここでMount Monadnock
favorite は null を返すが,NullPointerException は投げられない。 15.12.4.7 例: 評価の順序
インスタンスメソッド呼出し(15.12)の一部として,呼び出されるオブジェクトを指示する式がある。 この式はメソッド呼出しの実引数式のどの部分よりも前に完全に評価される。
class Test {
public static void main(String[] args) {
String s = "one";
if (s.startsWith(s = "two"))
System.out.println("oops");
}
}
.startsWith"の前の s は,実引数である s="two" よりも先に最初に評価される。
したがって,ターゲット参照としての文字列 "one" への参照は,局所変数sが文字列 "two" への参照に変更される前に記憶される。
その結果,startsWith メソッドは,実引数 "two" を持ったターゲットオブジェクト "one" に対して呼び出され,文字列 "one" は "two" で始まらないので,呼出しの結果は false とする。
したがって,テストプログラムは oops を表示しない。15.12.4.8 例: 上書き
次の例において,
class Point {
final int EDGE = 20;
int x, y;
void move(int dx, int dy) {
x += dx; y += dy;
if (Math.abs(x) >= EDGE || Math.abs(y) >= EDGE)
clear();
}
void clear() {
System.out.println("\tPoint clear");
x = 0; y = 0;
}
}
class ColoredPoint extends Point {
int color;
void clear() {
System.out.println("\tColoredPoint clear");
super.clear();
color = 0;
}
}
ColoredPoint は,その上位クラス Point で定義された抽象化 clear を継承する。
これは clear メソッドを自分のメソッドで上書きし,それは super.clear の形式を用いて上位クラスの clear メソッドを呼び出している。
clear の呼出しのターゲットオブジェクトが ColoredPoint であるときには常にこのメソッドが呼び出される。
さらに this のクラスは ColoredPoint であるとき,Point の中の move メソッドが codeColoredPoint の clear メソッドを呼び出し,次のテストプログラムは,
class Test {
public static void main(String[] args) {
Point p = new Point();
System.out.println("p.move(20,20):");
p.move(20, 20);
ColoredPoint cp = new ColoredPoint();
System.out.println("cp.move(20,20):");
cp.move(20, 20);
p = new ColoredPoint();
System.out.println("p.move(20,20), p colored:");
p.move(20, 20);
}
}
上書きは,"遅延束縛された自己参照"と呼ばれることがある。 この例では,p.move(20,20): Point clear cp.move(20,20): ColoredPoint clear Point clear p.move(20,20), p colored: ColoredPoint clear Point clear
Point.move (これは本当は this.clear の構文上の略記である)の中の clear への参照は,(コンパイル時に this の型に基づいて)"早く"選択されたメソッドではなく,(実行時に this で参照されるオブジェクトの実行時クラスに基づいて)"遅く"選択されたメソッドを呼び出すことを意味する。
これはプログラマに抽象化を拡張する強力な方法を提供するとともに,オブジェクト指向プログラミングの重要な考えでもある。15.12.4.9 例: super を用いたメソッド呼出し
上位クラスの上書きされたインスタンスメソッドは,その直接の上位クラスのメンバにアクセスするためにキーワード super を使用することによって,そのメソッド呼出しを含むクラス中のどの上書き宣言も無視してアクセスしてもよい。
インスタンス変数にアクセスするとき,super は this (15.11.2)をキャストしたものに等しいが,この等価性はメソッド呼出しに当てはまらない。
これを次の例で示す。
class T1 {
String s() { return "1"; }
}
class T2 extends T1 {
String s() { return "2"; }
}
class T3 extends T2 {
String s() { return "3"; }
void test() {
System.out.println("s()=\t\t"+s());
System.out.println("super.s()=\t"+super.s());
System.out.print("((T2)this).s()=\t");
System.out.println(((T2)this).s());
System.out.print("((T1)this).s()=\t");
System.out.println(((T1)this).s());
}
}
class Test {
public static void main(String[] args) {
T3 t3 = new T3();
t3.test();
}
}
型s()= 3 super.s()= 2 ((T2)this).s()= 3 ((T1)this).s()= 3
T1 及び T2 へのキャストは,呼び出されるメソッドを変更しない。
なぜなら,呼び出されるべきインスタンスメソッドは,this によって参照されるオブジェクトの実行時のクラスによって選択されるからである。
キャストはオブジェクトのクラスを変えない。
したがって,そのクラスがその規定された型と互換性があるかどうかを検査するだけとする。15.13 配列アクセス式
配列アクセス式は配列の構成要素である変数を参照する。
ArrayAccess: ExpressionName [ Expression ] PrimaryNoNewArray [ Expression ]配列アクセス式は,左角括弧の前の 配列参照式 (array reference expression) 及び角括弧の中の インデクス式 (index expression) の二つの副式からなる。 配列参照式は,名前又は配列生成式(15.10)でない一次式でもよいことに注意すること。
配列参照式の型は配列型(構成要素の型が T の配列をT[] と呼ぶ)でなければならない。
そうでなければ,コンパイル時エラーが発生する。
したがって,配列アクセス式の型は T とする。
インデクス式は,単項数値昇格(5.6.1)を受け,その昇格された型は int でなければならない。
配列参照の結果は型 T の変数,すなわち,インデクス式の値によって選択される配列中の変数とする。
この結果として生じる変数は,その配列の構成要素であり,配列参照が final 変数から得られたとしても,決して final とは考えられない。
15.13.1 配列アクセスの実行時評価
配列アクセス式は次の手順を用いて評価される。
- 最初に,その配列参照式が評価される。 もしこの評価が中途完了するならば,その配列アクセスは同じ理由で中途完了し,そのインデクス式は評価されない。
- そうでなければ,そのインデクス式が評価される。 もしこの評価が中途完了するならば,その配列アクセスは同じ理由で中途完了する。
- そうでなければ,もしその配列参照式の値が
nullならば,NullPointerExceptionが投げられる。 - そうでなければ,その配列参照式の値は配列を参照する。
もしそのインデクス式の値がゼロ未満であるか又はその配列の長さ以上であるならば,
IndexOutOfBoundsExceptionが投げられる。 - そうでなければ,その配列アクセスの結果は
インデクス式の値によって選択される配列中の型 T の変数とする
(この結果として生じる変数は,その配列の構成要素であり,その配列参照式が
final変数だとしても,決してfinalとみなされないことに注意すること。) 。
15.13.2 例: 配列アクセス評価順序
配列アクセスでは,その角括弧の左の式は,角括弧の中の式のどの部分よりも前に完全に評価される。 例えば,(あきらかに病的な)式a[(a=b)[3]] では,式 a が式(a=b)[3]よりも前に完全に評価される。
これは,式 (a=b)[3] が評価される間,式 a の元の値が取得及び記憶されていることを意味する。
したがって,a の元の値によって参照されたこの配列は,b によって参照されており及び今は a によっても参照されているもう一つの配列(たぶん同じ配列)の 3 番目の要素の値によってインデクスされる。
class Test {
public static void main(String[] args) {
int[] a = { 11, 12, 13, 14 };
int[] b = { 0, 1, 2, 3 };
System.out.println(a[(a=b)[3]]);
}
}
なぜならその病的な式の値は,14
a[b[3]],a[3] 又は 14 と等価であるからである。もしその角括弧の左の式の評価が中途完了するならば,その角括弧の中の式のどの部分も評価されない。 したがって,次の例は,
class Test {
public static void main(String[] args) {
int index = 1;
try {
skedaddle()[index=2]++;
} catch (Exception e) {
System.out.println(e + ", index=" + index);
}
}
static int[] skedaddle() throws Exception {
throw new Exception("Ciao");
}
}
なぜならjava.lang.Exception: Ciao, index=1
index への 2 の埋込み代入は決して起こらないからである。
もしその配列参照式が配列への参照の代わりに null を生成するならば,実行時に NullPointerException が投げられる。
しかし,その配列参照式のすべての部分が評価され,これらの評価が正常完了したあとに限る。
したがって,次の例は,
class Test {
public static void main(String[] args) {
int index = 1;
try {
nada()[index=2]++;
} catch (Exception e) {
System.out.println(e + ", index=" + index);
}
}
static int[] nada() { return null; }
}
なぜならjava.lang.NullPointerException, index=2
index への 2 の埋込み代入は,空ポインタの検査の前に起こるからである。
関係する例として,次のプログラムは,
class Test {
public static void main(String[] args) {
int[] a = null;
try {
int i = a[vamoose()];
System.out.println(i);
} catch (Exception e) {
System.out.println(e);
}
}
static int vamoose() throws Exception {
throw new Exception("Twenty-three skidoo!");
}
}
java.lang.Exception: Twenty-three skidoo!
NullPointerExceptionは決して起きない。
なぜなら,左辺のオペランドの値が null かどうかの検査を含むそのインデクス操作が起こる前に,そのインデクス式が完全に評価されるからである。15.14 後置式
後置式は++ 及び -- の後置演算子の使用を含む。
また,15.8で議論したように,名前を一次式とは考えずに,文法におけるあいまいさを避けるために区別して扱う。
それらは,ここに限れば後置式の優先順位のレベルで交換可能になる。
PostfixExpression: Primary ExpressionName PostIncrementExpression PostDecrementExpression
15.14.1 後置増分演算子 ++
PostIncrementExpression: PostfixExpression ++
++ 演算子があとに続いた後置式は後置増分式とする。
その後置式の結果は数値型の変数でなければならない。
そうでなければコンパイル時エラーが発生する。
その後置増分式の型は,その変数の型とする。
後置増分式の結果は,変数ではなく,値とする。
実行時に,もしそのオペランド式の評価が中途完了するならば,その後置増分式も同じ理由で中途完了し,増分は起こらない。
そうでなければ,値 1 が変数の値に加えられ,その合計がその変数に記憶される。
その加算の前に,二項数値昇格(5.6.2)がその値 1 及びその変数の値に実行される。
必要ならば,その合計は,記憶される前にその変数の型へのプリミティブ型の縮小変換(5.1.3)によって縮小される。
その後置増分式の値は,その新しい値が記憶される前の変数の値とする。
上記の二項数値昇格は,数値集合変換(5.1.8)を含むかもしれないことに注意すること。 必要ならば,数値集合変換は,その加算に対して,それが変数に記憶される前に適用される。
final と宣言された変数を加算することはできない。
なぜなら,final 変数のアクセスが式として使用されたとき,その結果は値であり,変数ではないからである。
したがって,それを後置増分演算子のオペランドとして使用することはできない。
15.14.2 後置減分演算子 --
PostDecrementExpression: PostfixExpression --
-- 演算子があとに続いた後置式は後置減分式とする。
その後置式の結果は数値型の変数でなければならない。
そうでなければコンパイル時エラーが発生する。
その後置減分式の型は,その変数の型とする。
後置減分式の結果は,変数ではなく値とする。
実行時に,もしオペランド式の評価が中途完了するならば,その後置減分式も同じ理由で中途完了し,減分は起こらない。
そうでなければ,値 1 が変数の値から減じられ,その差分がその変数に記憶される。
その減算の前に,二項数値昇格(5.6.2)がその値 1 及びその変数の値に実行される。
必要ならば,その差分は,その新しい値が記憶される前に,その変数の型へのプリミティブ型の縮小変換(5.1.3)によって縮小される。
後置減分式の値は,新しい値が記憶される前の変数の値とする。
上記の二項数値昇格は,数値集合変換(5.1.8)を含むかもしれないことに注意すること。 必要ならば,数値集合変換は,その差分に対して,それが変数に記憶される前に適用される。
final と宣言された変数を減算することはできない。
なぜなら,final 変数のアクセスが式として使用されたとき,その結果は値であり,変数ではないからである。
したがって,それを後置減分演算子のオペランドとして使用することはできない。
15.15 単項演算子
単項演算子 (unary operators) は,+,-,++,--,~,! 及びキャスト演算子を含む。
単項演算子をもつ式は,右から左へグループ化される。
つまり,-~x は,-(~x) と同じ意味とする。
UnaryExpression: PreIncrementExpression PreDecrementExpression + UnaryExpression - UnaryExpression UnaryExpressionNotPlusMinus PreIncrementExpression: ++ UnaryExpression PreDecrementExpression: -- UnaryExpression UnaryExpressionNotPlusMinus: PostfixExpression ~ UnaryExpression ! UnaryExpression CastExpression15.16の次の生成規則を,便宜上ここで繰り返す。
CastExpression: ( PrimitiveType ) UnaryExpression ( ReferenceType ) UnaryExpressionNotPlusMinus
15.15.1 前置増分演算子 ++
++ 演算子が先行した単項式は前置増分式とする。
その単項式の結果は数値型の変数でなければならない。
そうでなければ,コンパイル時エラーが発生する。
その前置増分式の型は,その変数の型とする。
その前置増分式の結果は,変数ではなく値とする。
実行時に,もしそのオペランド式の評価が中途完了するならば,前置増分式は同じ理由で中途完了し,加算は起こらない。
そうでなければ,その値 1 がその変数の値に加えられ,その合計はその変数に記憶される。
その加算の前に,二項数値昇格(5.6.2)が,その値 1 及びその変数の値に実行される。
必要ならば,その合計は,記憶される前に,その変数の型へのプリミティブ型の縮小変換(5.1.3)によって縮小される。
その前置増分式の値は,その新しい値が記憶された後の変数の値とする。
上記の二項数値昇格は,数値集合変換(5.1.8)を含むかもしれないことに注意すること。 必要ならば,数値集合変換は,その加算に対して,それが変数に記憶される前に適用される。
final と宣言された変数を加算することはできない。
なぜなら,final 変数へのアクセスが式として使用されたとき,その結果は値であり,変数ではないからである。
したがって,それを前置増分演算子のオペランドとして使用することはできない。
15.15.2 前置減分演算子 --
-- 演算子が先行した単項式は前置減分式とする。
その単項式の結果が数値型の変数でなければならない。
そうでなければ,コンパイル時エラーが発生する。
その前置減分式の型は,その変数の型とする。
その前置減分式の結果は,変数ではなく,値とする。
実行時に,もしオペランド式の評価が中途完了するならば,前置減分式は同じ理由で中途完了し,減算は起こらない。
そうでなければ,その値 1 がその変数の値から引かれ,その差分はその変数に記憶される。
その減算の前に,二項数値表現(5.6.2)がその値 1 及びその変数の値に実行される。
必要ならば,その差分は,記憶される前に,その変数の型へのプリミティブ型の縮小変換(5.1.3)によって縮小される。
その前置減分式の値は,その新しい値が記憶された後の変数の値とする。
上記の二項数値昇格は,値集合変換(5.1.8)を含むかもしれないことに注意すること。
必要ならば,数値集合変換は,その減算に対して,それが変数に記憶される前に適用される。
final と宣言された変数を減算することはできない。
なぜなら,final 変数へのアクセスが式として使用されたとき,その結果は値であり,変数ではないからである。
したがって,それを前置増分演算子のオペランドとして使用することはできない。
15.15.3 単項プラス演算子 +
単項 + 演算子式のオペランドの型はプリミティブ数値型でなければならない。
そうでなければ,コンパイル時エラーが発生する。
単項数値昇格(5.6.1)がそのオペランドに実行される。
その単項加算式の型は,そのオペランドの昇格された型とする。
そのオペランドの結果が変数だとしても,その単項加算式の結果は変数ではなく値とする。実行時に,その単項加算式の値はそのオペランドの昇格された値とする。
15.15.4 単項マイナス演算子 -
単項 - 演算子式のオペランドの型は,プリミティブ数値型でなければならない。
そうでなければ,コンパイル時エラーが発生する。
単項数値昇格(5.6.1)が,そのオペランドに実行される。
その単項マイナス式の型は,昇格されたオペランドの型とする。単項数値昇格は,数値集合変換(5.1.8)を実行することに注意すること。 昇格されたオペランド値がどの数値集合から引き出されても,単項否定演算が実行され,及びその結果が同じ数値集合から引き出される。 その単項否定演算が実行され,及びその結果がそれと同じ数値集合から引き出される。 したがって,その結果は,さらに数値集合変換がおこなわれる。
実行時に,その単項マイナス式の値は,そのオペランドの昇格した値の算術的否定とする。
整数値において,否定はゼロからの減算と同じとする。
Javaプログラム言語は,整数において2の補数表現を使用する。
2の補数の範囲は対称ではないので,最大の負の int 又は long の否定は最大の負の数となる。
この場合はオーバフローが起こるが,例外は投げられない。
すべての整数値 x において,-x は (~x)+1 に等しい。
浮動小数点値において,否定はゼロからの引き算と同じでない。
なぜなら,もし x が +0.0 ならば,0.0-x は +0.0 に等しいが,-x は -0.0 に等しいからである。
単項マイナスは,単に浮動小数点の符号を逆にする。
特に重要な場合を以下に示す。
- もしそのオペランドがNaNならば,その結果はNaN(NaNは符号を持たない)とする。
- もしそのオペランドが無限大ならば,その結果は反対の符号の無限大とする。
- もしそのオペランドがゼロならば,その結果は反対の符号のゼロとする。
15.15.5 ビット単位の補数演算子 ~
単項 ~ 式のオペランドの型は,プリミティブの整数的な型でなければならない。
そうでなければ,コンパイル時エラーが発生する。
単項数値昇格(5.6.1)は,そのオペランドに対して実行される。
単項のビット単位の補数式の型は,そのオペランドの昇格された型とする。
実行時に,単項のビット単位の補数式の値は,そのオペランドの昇格された値のビット単位の補数となる。
すべての場合において,~x は (-x)-1 に等しいことに注意すること。
15.15.6 論理的な補数演算子 !
単項 ! 演算子のオペランド式の型は boolean でなければならない。
そうでなければ,コンパイル時エラーが発生する。
単項論理補数式の型は boolean とする。
実行時に,その単項論理補数式は,もしそのオペランドの値が false ならば true となり,もしそのオペランドの値が true ならば false となる。
15.16 キャスト式
キャスト式は,実行時にある数値型の値を別の数値型の同様な値に変換すること,コンパイル時にある式の型がboolean かどうかを確認すること,又は実行時にある参照値が規定された参照型と互換性のあるクラスのオブジェクトを参照しているかどうかを検査することなどを実行する。
CastExpression: ( PrimitiveType Dimsopt ) UnaryExpression ( ReferenceType ) UnaryExpressionNotPlusMinusUnaryExpression と UnaryExpressionNotPlusMinus の間の区別の議論については,15.15を参照すること。
キャスト式の型は,括弧内に出現する名前の型とする (括弧及び括弧が含む型をキャスト演算子 (cast operator) と呼ぶことがある。)。 キャスト式の結果は,そのオぺランドの式の結果が変数だとしても,変数ではなく値とする。
キャスト演算子は,型 float 又は double の値に対する数値集合(4.2.3)の選択には効果がない。
その結果,FP厳密(15.4)ではない式の中の型 float へのキャストは,その値を単精度数値集合の要素に変換する必要はなく,及びFP厳密でない式の中の型 double へのキャストは,その値を倍精度数値集合の要素に変換する必要はない。
実行時に,オぺランドの値をキャスト変換(5.5)によって,そのキャスト演算子で規定された型に変換する。
Java言語では,すべてのキャストが許されるわけではない。
あるキャストは,コンパイル時エラーを生じる。
例えば,プリミティブ値は,参照型にキャストしてはいけない。
あるキャストは,コンパイル時に実行時に常に正しいことを保証できる。
例えば,あるクラス型の値を,その上位クラスの型に変換することは常に正しい。
このようなキャストは,実行時に特別な動作を要求しないほうがよい。
最後に,あるキャストは,常に正しいか常に正しくないかをコンパイル時に特定できない。
そのようなキャストは,実行時に検査が必要とする。
もし受け入れられないキャストを実行時に検出したならば,ClassCastException が投げられる。
15.17 乗除演算子
演算子*,/ 及び % は,乗除演算子 (multiplicative operators) と呼ぶ。
これらは同じ優先順位をもち,構文的に左結合とする(左から右にグループ化する。)。
MultiplicativeExpression: UnaryExpression MultiplicativeExpression * UnaryExpression MultiplicativeExpression / UnaryExpression MultiplicativeExpression % UnaryExpression乗除演算子のオぺランドのそれぞれの型は,プリミティブ数値型でなければならない。 そうでなければ,コンパイル時エラーが発生する。 そのオぺランドに対して,二項数値昇格が実行される(5.6.2)。 乗除式の型は,そのオぺランドの昇格された型とする。 もしこの昇格された型が
int 又は long であるならば,整数演算を実行する。
もしこの昇格された型が float 又は double であるならば,浮動小数点演算を実行する。二項数値昇格が,数値集合変換(5.1.8)を実行することに注意すること。
15.17.1 乗算演算子 *
二項 * 演算子は乗算を実行し,そのオぺランドの積を生成する。
もしオぺランドの式が副作用をもたないならば,乗算は可換的演算とする。
オぺランドがすべて同じ型のとき,整数乗算は結合的であるが,浮動小数点乗算は結合的ではない。もし整数乗算がオーバフローしたならば,その結果は数学的な積を十分大きな2の補数形式で表現したときの低位ビットとする。 その結果として,もしオーバフローが発生したならば,その結果の符号は二つのオぺランド値の数学的積の符号と同じでないかもしれない。
浮動小数点乗算の結果は,次のようにIEEE 754の算術の規則に従う。
- もしどちらかのオぺランドがNaNであるならば,その結果はNaNとする。
- もしその結果がNaNでないならば,両方のオぺランドが同じ符号であるならばその結果の符号を正とし,それらのオぺランドが異なる符号であるならばその結果の符号は負とする。
- 無限大とゼロの乗算の結果はNaNとする。
- 無限大と有限値の乗算の結果は,符号付き無限大とする。 その符号は上述の規則によって決定する。
- その他の場合に,無限大及びNaNを含まなければ,正確な数学的な積を計算する。
浮動小数点数値集合は,次のように選択される。
- もし乗算式がFP厳密(15.4)であるならば,
- もし乗算式がFP厳密でないならば,
-
次に,値はその積を表現するために選択された数値集合から選択されねばならない。
もし積の大きさが表現不可能なほど大きいならば,演算オーバフローと呼ぶ。
その結果は適切な符号の無限大とする。
もし積の大きさが表現不可能なほど小さいならば,演算アンダフローと呼ぶ。
その結果は適切な符号のゼロとする。
そうでなければ,積はIEEE 754の直近への丸めモードを使用して選択された数値集合の中の直近値に丸められる。
Javaプログラム言語は,IEEE 754 によって定義された緩やかなアンダフロー(4.2.4)のサポートを要求する。
* は決して実行時例外を投げない。15.17.2 除算演算子 /
二項 / 演算子は除算を実行し,そのオぺランドの商を生成する。
その左辺オぺランドは被除数であり,その右辺オぺランドは除数とする。
整数除算は結果を 0 方向に丸める。
つまり,二項数値昇格(5.6.2)の後の整数のオぺランド n 及び d に対して生成される商は,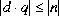 を満足しながら,その大きさが可能な限り大きい整数値 q とする。
さらに,
を満足しながら,その大きさが可能な限り大きい整数値 q とする。
さらに,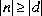 であって,n 及び d が同じ符号をもつとき,q は正とする。
しかし,
であって,n 及び d が同じ符号をもつとき,q は正とする。
しかし,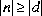 であって,n 及び d が反対の符号をもつとき,q は負とする。
この規則を満足しない特別な場合が一つだけ存在する。
もしその被除数がその型に対して可能な最大の大きさの負の整数であり,その除数が
であって,n 及び d が反対の符号をもつとき,q は負とする。
この規則を満足しない特別な場合が一つだけ存在する。
もしその被除数がその型に対して可能な最大の大きさの負の整数であり,その除数が -1 であるならば,整数オーバフローが発生し,その結果はその被除数と同じとする。
オーバフローにもかかわらず,この場合は例外は投げられない。
一方,整数の除算における除数の値が 0 ならば,ArithmeticException が投げられる。
浮動小数点の除算の結果は,IEEE算術の規定によって次のように決定される。
- もしどちらかのオぺランドがNaNであるならば,その結果はNaNとする。
- もしその結果がNaNでないならば,両方のオぺランドが同じ符号をもてば,その結果の符号は正であり,両方のオぺランドが異なる符号をもてば,その結果の符号は負とする。
- 無限大による無限大の除算の結果はNaNとする。
- 有限値による無限大の除算の結果は符号付き無限大とする。 その符合は上述の規則によって決定される。
- 無限大による有限値の除算の結果は符号付きゼロとする。 その符号は上述の規則によって決定される。
- ゼロによるゼロの除算の結果はNaNとする。 ゼロ以外の有限値によるゼロの除算の結果は符号付きのゼロとする。 その符合は上述の規則によって決定される。
- ゼロによるゼロ以外の有限値の除算の結果は,符号付き無限大とする。 その符合は上述の規則によって決定する。
- その他の場合に,無限大及びNaNを含まなければ,正確な数学的な商を計算する。
浮動小数点数値集合は,次のように選択される。
- もし除算式がFP厳密(15.4)であるならば,
- 除算式がFP厳密でない場合には,
-
次に,値はその商を表現するために選択された数値集合から選択されねばならない。
もし商の大きさが表現不可能なほど大きいならば,演算オーバフローと呼ぶ。
その結果は適切な符合の無限大とする。
もし商の大きさが表現不可能なほど小さいならば,演算アンダフローと呼ぶ。
その結果は適切な符合のゼロとする。
そうでなければ,商はIEEE 754の直近への丸めモードを使用して選択された数値集合の中の直近値に丸められる。
Javaプログラム言語は,IEEE 754で定義された 緩やかなアンダフロー (4.2.4)のサポートを要求する。
/ の評価は決して実行時例外を投げない。15.17.3 剰余演算子 %
二項 % 演算子は,暗黙の除算によってそのオぺランドの剰余を生成する。
その左辺オぺランドは被除数であり,及びその右辺オぺランドは除数とする。C及びC++では,剰余演算子は整数的なオぺランドだけを受け入れるが,Javaプログラム言語では浮動小数点のオペランドも受け入れる。
二項数値昇格(5.6.2)の後の整数のオぺランドに対する剰余演算は,(a/b)*b+(a%b) が a に等しいように結果を生成する。
この恒等式は,被除数をその型に対する可能な最大の大きさの負の整数であり,及び除数が -1 (その剰余は 0)である特別な場合においても成立する。
この規則から,その剰余演算の結果は,その被除数が負である場合に限り負であり,その被除数が正である場合に限り正であることが求められる。
さらに,その結果の大きさは常にその除数の大きさより小さい。
もし整数の剰余演算子に対する除数の値が 0 であるならば,ArithmeticException が投げられる。
5%3 の結果は 2 (5/3 の結果は 1であることに注意すること) 5%(-3) の結果は 2 (5/(-3) の結果は -1であることに注意すること) (-5)%3 の結果は -2 ((-5)/3 の結果は -1であることに注意すること) (-5)%(-3) の結果は -2 ((-5)/(-3) の結果は 1であることに注意すること)
% 演算子によって計算される浮動小数点剰余演算の結果は,IEEE 754で定義された剰余演算によって生成される結果とは同じではない。
IEEE 754の剰余演算は,切り捨て除算ではなく,丸め除算によって計算し,及びその振舞いは通常の整数剰余演算子とは同じではない。
代わりに,Javaプログラム言語では,整数剰余演算子と同様に振る舞うように,浮動小数点演算に対する % 演算を定義する。
これは,Cライブラリ関数の fmod に相当する。
IEEE 754の剰余演算は,Javaのライブラリルーチンの Math.IEEEremainder (20.11.14)によって計算できる。
浮動小数点演算の結果は,IEEE算術の規則によって次のように決定される。
- もしどちらかのオぺランドがNaNであるならば,その結果はNaNとする。
- もしその結果がNaNでなければ,その結果の符号は被除数の符合と同じとする。
- もし被除数が無限大,除数がゼロ又はその両方であるならば,その結果はNaNとする。
- もし被除数が有限及び除数が無限大であるならば,その結果は被除数に等しい。
- もし被除数がゼロ及び除数が有限であるならば,その結果は被除数に等しい。
- その他の場合には,無限大,ゼロ及びNaNのいずれも含まれなければ,除数 d による被除数 n の除算から得られる浮動小数点剰余 r は,数学的関係
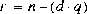 によって定義される。
ここで,q は,
によって定義される。
ここで,q は,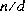 が負の場合に限り負の整数,
が負の場合に限り負の整数,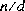 が正の場合に限り正の整数であり,及びその大きさは,n 及び d の真の数学的な商の大きさを超えない範囲で,可能な限り大きい。
が正の場合に限り正の整数であり,及びその大きさは,n 及び d の真の数学的な商の大きさを超えない範囲で,可能な限り大きい。
0 になるにもかかわらず,浮動小数点剰余演算子 % の評価は決して実行時例外を投げない。
オーバフロー,アンダフロー及び精度の損失は発生しない。
5.0%3.0 の結果は 2.0 5.0%(-3.0) の結果は 2.0 (-5.0)%3.0 の結果は -2.0 (-5.0)%(-3.0) の結果は -2.0
15.18 加減演算子
演算子+ 及び - は加減演算子 (additive operators) と呼ばれる。
これらは同じ優先順位をもち,構文的に左結合とする(左から右にグループ化する。)。
AdditiveExpression: MultiplicativeExpression AdditiveExpression + MultiplicativeExpression AdditiveExpression - MultiplicativeExpressionもし
+ 演算子のいずれかのオぺランドの型が String であるならば,その演算は文字列の連結とする。
そうでなければ,+ 演算子の各オペランドの型は,プリミティブ数値型でなければならない。
そうでなければ,コンパイル時エラーが発生する。
すべての場合において,二項 - 演算子の各オペランドは,プリミティブ数値型でなければならない。
そうでなければ,コンパイル時エラーが発生する。
15.18.1 文字列連結演算子 +
もし一つのオペランドの式だけが型 String であるならば,実行時に文字列を生成するために,他方のオペランドに対して文字列変換を実行する。
その結果は,二つのオペランドの文字列を連結して新たに作成した String オブジェクトへの参照とする。
新たに作成した文字列の中では,左辺オぺランドの文字が右辺オぺランドの文字に先行する。15.18.1.1 文字列変換
文字列変換 (string conversion) によって,いかなる型もString に変換できる。
最初に,プリミティブ型 T の値 x を,適切なクラスインスタンス生成式への実引数にその値を与えたかのように参照値に変換される。
- もし T が
booleanであるならば,newBoolean(x)を使用する。 - もし T が
charであるならば,newCharacter(x)を使用する。 - もし T が
byte,short又はintであるならば,newInteger(x)を使用する。 - もし T が
longであるならば,newLong(x)を使用する。 - もし T が
floatであるならば,newFloat(x)を使用する。 - もし T が
doubleであるならば,newDouble(x)を使用する。
String に変換される。
この後は,参照値だけを考慮する必要がある。
もしその参照が null であるならば,それは文字列 "null" (四つのASCII文字 n,u,l,l)に変換される。
そうでなければ,その変換は,その参照されているオブジェクトのメソッド toString を実引数なしで呼び出したかのように実行される。
しかし,もしメソッド toString の呼出し結果が null であるならば,文字列 "null" が代わりに使用される。
toString メソッドは,基本クラス Object によって定義されている。
多くのクラスがそれを上書きしており,特にBoolean,Character,Integer,Long,Float,Double 及び String がある。
15.18.1.2 文字列連結の最適化
処理系は,中間的なString オブジェクトの作成及び廃棄を避けるために,変換及び連結を一段階で実行してもよく,Javaコンパイラは,繰り返される文字列連結の性能向上を目的として,式の評価によって作成される中間的な String オブジェクトの数を減らすために,StringBuffer クラス又は同様の技術を使用してもよい。プリミティブ型に対しては,処理系はプリミティブ型から文字列に直接変換することによって,ラッパーオブジェクトの作成を最適化してもよい。
15.18.1.3 文字列連結の例
式の例を次に示す。
これは次の結果を生成する。"The square root of 2 is " + Math.sqrt(2)
"The square root of 2 is 1.4142135623730952"
+ 演算子は,たとえそれが文字列連結又は加算を表現するために型解析によって後から決定されても,構文的に左結合とする。
望む結果を得るためには,注意が要求されることもある。
例えば,次の式は,
常に次の式を意味するとみなす。a + b + c
したがって,次の式の結果は(a + b) + c
次の通りとする。1 + 2 + " fiddlers"
しかし,次の式の結果は,"3 fiddlers"
次の通りとする。"fiddlers " + 1 + 2
ここで少し面白い例を次に示す。"fiddlers 12"
class Bottles {
static void printSong(Object stuff, int n) {
String plural = (n == 1) ? "" : "s";
loop: while (true) {
System.out.println(n + " bottle" + plural
+ " of " + stuff + " on the wall,");
System.out.println(n + " bottle" + plural
+ " of " + stuff + ";");
System.out.println("You take one down "
+ "and pass it around:");
--n;
plural = (n == 1) ? "" : "s";
if (n == 0)
break loop;
System.out.println(n + " bottle" + plural
+ " of " + stuff + " on the wall!");
System.out.println();
}
System.out.println("No bottles of " +
stuff + " on the wall!");
}
}
printSong はある童謡の替え歌を印刷する。
stuff として人気のある値は "pop" 及び "beer" を含む。
n としても最も人気がある値は 100 とする。
ここで,Bottles.printSong("slime", 3) の結果の出力を次に示す。
このコードの中では,複数形の"3 bottles of slime on the wall, 3 bottles of slime; You take one down and pass it around: 2 bottles of slime on the wall! 2 bottles of slime on the wall, 2 bottles of slime; You take one down and pass it around: 1 bottle of slime on the wall! 1 bottle of slime on the wall, 1 bottle of slime; You take one down and pass it around: No bottles of slime on the wall!
bottles"よりも単数形の"bottle"が適切なときは,単数形を注意深く条件にしたがって生成することに注意すること。
次のような長い文字列定数の分割するために,文字列連結演算子を使用した方法にも注意すること。
これを,ソースコード中では,不便な長い行を避けるために二つに分割している。"You take one down and pass it around:"
15.18.2 数値型加減演算子 ( + 及び - )
二項 + 演算子は,二つのオぺランドが数値型のときに加算を実行し,そのオぺランドの和を生成する。
二項 - 演算子は,減算を実行し,二つの数値オぺランドの差を生成する。
そのオペランドに対して二項数値昇格が実行される (5.6.2)。
数値オぺランドに対する加減式の型は,そのオぺランドの昇格された型とする。
この昇格された型が int 又は long ならば,整数算術が実行される。
この昇格された型が float 又は double ならば,浮動小数点算術が実行される。
二値数値昇格は数値集合変換(5.1.8)を実行することに注意すること。
もしそのオぺランドの式が副作用をもたないならば,加算は可換的な演算とする。 オペランドがすべて同じ型のとき,整数加算は結合的であるが,浮動小数点加算は結合的ではない。
もし整数の加算がオーバフローしたならば,その結果は数学的な和を十分大きな2の補数形式で表現したときの低位ビットとする。 オーバフローが発生すれば,その結果の符号は二つのオぺランド値の数学的和の符号と同じではない。
浮動小数点加算の結果は,次のIEEE 754算術の規則を用いて決定される。
- もしどちらかのオぺランドがNaNであるならば,その結果はNaNとする。
- 異なる符号の二つの無限大の和は,NaNとする。
- 同じ符号の二つの無限大の和は,その符号の無限大とする。
- 無限大及び有限値の和は,その無限大オぺランドに等しい。
- 異なる符号の二つのゼロの和は,正のゼロとする。
- 同じ符号の二つのゼロの和は,その符号のゼロとする。
- ゼロ及び非ゼロの有限値の和は,その非ゼロのオぺランドに等しい。
- 同じ大きさ及び異なる符号の二つの非ゼロの有限値の和は,正のゼロとする。
- そうでなければ,無限大,NaN及びゼロを含まず,及びそのオぺランドが同じ符号をもつ又は異なる大きさをもつならば,その正確な数学的和が計算される。
浮動小数点数値集合は,次のように選択される。
- もしその加算式がFP厳密(15.4)であるならば,
- もしその加算式がFP厳密でないならば,
-
次に,値はその和を表現するために選択された数値集合から選択されねばならない。
もし和の大きさが表現不可能なほど大きいならば,演算オーバフローと呼ぶ。
その結果は適切な符合の無限大とする。
そうでなければ,和はIEEE 754の直近への丸めモードを使用して選択された数値集合の中の直近値に丸められる。
Javaプログラム言語は,IEEE 754で定義された緩やかなアンダフロー(4.2.4)のサポートを要求する。
- 演算子は,数値型の二つのオぺランドに適用したときに減算を実行し,そのオぺランドの差を生成する。
その左辺オぺランドは被減数であり,及びその右辺オぺランドは減数とする。
整数及び浮動小数点減算の両方に対して,常に a-b は a+(-b) と同じ結果を生成する。
整数値についてはゼロからの減算は符号反転と同じであるが,浮動小数点オぺランドについては,ゼロからの減算は符号反転と同じではないことに注意すること。
なぜなら,x が +0.0 ならば 0.0-x は +0.0 に等しいが,-x は -0.0 に等しいからである。
オーバフロー,アンダフロー又は情報の損失が発生するかもしれない事実にもかかわらず,数値加減演算子の評価は決して実行時例外を投げない。
15.19 シフト演算子
シフト演算子 (shift operators) は,左シフト<<,符号付き右シフト >>,及び符号なし右シフト >>>を含む。
それらは構文的に左結合とする(左から右にグループ化する。)。
シフト演算子の左辺オぺランドはシフトされる値であり,右辺オぺランドはシフト幅を規定する。
ShiftExpression: AdditiveExpression ShiftExpression << AdditiveExpression ShiftExpression >> AdditiveExpression ShiftExpression >>> AdditiveExpressionシフト演算子のオぺランドのそれぞれの型は,プリミティブな整数的な型でなければならない。 そうでなければ,コンパイル時エラーが発生する。 そのオペランドに対して二項数値昇格(5.6.2)は実行しないが,単項数値昇格(5.6.1)は各オぺランドに対して個々に実行される。 そのシフト演算式の型は,その左辺オぺランドの昇格された型とする。
もしその左辺オぺランドの昇格された型が int であるならば,その右辺オぺランドの下位5ビットだけをシフト幅として使用する。
それはその右辺オペランドが,マスク値 0x1f を用いたビット単位のAND演算子 & (15.22.1)に従うかのようにとする。
したがって,実際に使用するシフト幅は0から31までの範囲とする。
もしその左辺オぺランドの昇格された型が long であるならば,その右辺オぺランドの下位6ビットだけをシフト幅として使用する。
それはその右辺オペランドが,マスク値 0x3f を用いたビット単位のAND演算子 & (15.22.1)に従うかのようにとする。
したがって,実際に使用されるシフト幅は0から63までの範囲とする。
実行時には,シフト演算はその左辺オぺランド値の2の補数の整数表現に対して実行される。
n<<s の値は,n を s ビット位置だけ左にシフトした値とする。
これは(オーバフローが発生したとしても)2の s 乗の乗算に等しい。
n>>s の値は,n を符号拡張を伴って s ビット位置だけ右にシフトした値とする。
この結果の値は 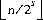 とする。
とする。
n の非負数の値に対しては,これは整数除算演算子/によって計算される,2の s 乗の切り捨て整数除算に等しい。
n>>>s の値は,ゼロ拡張を伴ってn を s ビット位置分右にシフトした値とする。
もし n が正であるならば,その結果は n>>s と同じとする。
もし nが負であるならば,その結果はその左辺オぺランドの型が int ならば式 (n>>s)+(2<<~s) と等しく,その左辺オぺランドの型が long ならば式 (n>>s)+(2L<<~s)に等しい。
追加された項 (2<<~s) 又は (2L<<~s) は,伝播された符号ビットを除去する
(シフト演算子の右辺オぺランドの暗黙のマスクのために,シフト幅としての ~s は,int 値をシフトするときは 31-s に等しく,long 値をシフトするときは 63-s に等しいことに注意すること。)。
15.20 関係演算子
関係演算子 (relational operators) は,構文的に左結合とする(左から右にグループ化する。)。 しかし,この事実は実用的ではない。 例えば,a<b<c を (a<b)<c と構文解析するが,これは常にコンパイル時エラーとする。
なぜなら,a<b の型は常に boolean であり,及び< は boolean 値に対する演算子ではないからである,
RelationalExpression: ShiftExpression RelationalExpression < ShiftExpression RelationalExpression > ShiftExpression RelationalExpression <= ShiftExpression RelationalExpression >= ShiftExpression RelationalExpression instanceof ReferenceType関係式の型は,常に
boolean とする。15.20.1 数値比較演算子 <, <=, >, 及び >=
数値比較演算子のそれぞれのオぺランドの型は,プリミティブ数値型でなければならない。
そうでなければ,コンパイル時エラーが発生する。
そのオぺランドに対して二項数値昇格が実行される (5.6.2)。
もしそのオペランドの昇格された型が int 又は long であるならば,符号付き整数比較が実行される。
もしこの昇格された型が float 又は double であるならば,浮動小数点比較が実行される。二値数値昇格は,数値集合変換(5.1.8)を実行することに注意すること。 それらの値を表現するためにどの数値集合を用いても,比較は浮動小数点値に対して正確に実行される。
浮動小数点比較の結果は,IEEE 754標準の規定によって決定されるように,次のとおりとする。
- もしどちらかのオぺランドがNaNであるならば,その結果は
falseとする。 - NaN以外のすべての値は,すべての有限値よりも小さい負の無限大及びすべての有限値よりも大きい正の無限大の間に順序付けられる。
- 正のゼロ及び負のゼロは,等しいとみなされる。
したがって,例えば,
-0.0<0.0はfalseであるが,-0.0<=0.0はtrueとする (しかし,メソッドMath.min及びMath.maxは,厳密に負のゼロを正のゼロよりも小さいと扱うことに注意すること。)。
<演算子によって生成される値は,もしその左辺オぺランドの値が右その辺オぺランドの値より小さければ,trueであり,そうでなければfalseとする。<=演算子によって生成される値は,もしその左辺オぺランドの値がその右辺オぺランドの値より小さい又は等しければ,trueであり,そうでなければfalseとする。>演算子によって生成される値は,その左辺オぺランドの値がその右辺オぺランドの値より大きければ,trueであり,そうでなければfalseとする。>=演算子によって生成される値は,その左辺オぺランドの値がその右辺オぺランドの値より大きい又は等しければ,trueであり,そうでなければfalseとする。
15.20.2 型比較演算子 instanceof
instanceof 演算子の RelationalExpression オぺランドの型は,参照型又は空型でなければならない。
そうでなければ,コンパイル時エラーが発生する。
instanceof 演算子の後に記述する ReferenceType は,参照型又は空型でなければならない。
そうでなければ,コンパイル時エラーが発生する。
実行時に,instanceof演算子の結果は,もし RelationalExpression の値が null でなく,その参照が例外 ClassCastException を投げずに ReferenceType にキャスト(15.16)できるならば,trueとする。
そうでなければ,その結果は false とする。
もし RelationalExpression の ReferenceType へのキャストがコンパイル時エラーとして拒否されれば,instanceof 関係式も同様にコンパイル時エラーを生じる。
このような状況では,instanceof 式の結果は決して true ではない。
class Point { int x, y; }
class Element { int atomicNumber; }
class Test {
public static void main(String[] args) {
Point p = new Point();
Element e = new Element();
if (e instanceof Point) { // compile-time error
System.out.println("I get your point!");
p = (Point)e; // compile-time error
}
}
}
(Point)eは 間違っている。
なぜなら Element のインスタンス及びその可能な下位クラス(ここでは示されていない)は,Point の下位クラスのインスタンスになることができないからとする。
instanceof 式もまさしく同じ理由で間違っている。
一方,もしPointが次のようにElementの下位クラス(この例では明らかに奇妙な表記である)ならば,
class Point extends Element { int x, y; }
instanceof式は意味があり妥当となる。
そのキャスト (Point)e は決して例外を投げない。
なぜなら,もし値 e が型 Point に正しくキャストできないならば,そのキャストは実行されないからとする。15.21 等価演算子
等価演算子は,構文的に左結合とする(左から右にグループ化する。)。 しかし,この事実は本質的には決して実用的ではない。 例えば,a==b==c は (a==b)==c と構文解析する。
a==b の結果の型は,常に boolean であり,したがって c は型 boolean でなければならない。
そうでなければ,コンパイル時エラーが発生する。
つまり,a==b==c は ,a, b 及び c がすべて等しいかどうかを検査しない。
EqualityExpression: RelationalExpression EqualityExpression == RelationalExpression EqualityExpression != RelationalExpression
== (等価)及び != (不等価)演算子は,優先順位が低いという点を除いては関係演算子と類似している。
したがって,a<b==c<d は,a<b 及び c<d が同じ真値をもつときには,常に trueとする。
等価演算子は,数値型の二つのオぺランド,型 boolean の二つのオぺランド又はそれぞれが参照型若しくは空型の二つのオぺランドを比較するために使用してよい。
そうでなければ,コンパイル時エラーが発生する。
等価式の型は,常に boolean とする。
すべての場合において,a!=b は !(a==b) と同じ結果を生成する。
もしオぺランド式が副作用をもたないならば,その等価演算子は可換的とする。
15.21.1 数値等価演算子 == 及び !=
もし等価演算子の両方のオぺランドがプリミティブ数値型であるならば,そのオぺランドに対して二項数値昇格(5.6.2)が実行される。
もしその昇格された型が int 又は long であるならば,整数等価試験が実行される。
もしその昇格された型が float 又は double であるならば,浮動小数点等価試験が実行される。二値数値昇格は,数値集合変換(5.1.8)を実行することに注意すること。 比較は,それらの値を表現するためにどの数値集合数値集合を用いても,浮動小数点値を正確に処理する。
浮動小数点等価試験は,IEEE 754標準の規則にしたがって,次のように実行される。
- もしどちらかのオぺランドがNaNであるならば,
==の結果はfalseであるが,!=の結果はtrueとする。 実際に,試験x!=xの結果は,xの値が NaNの場合に限り真とする (値が NaNかどうかを試験するために,メソッドFloat.isNaN及びDouble.isNaNも使用してよい。)。 - 正及び負のゼロは,等価と見なす。
したがって,例えば,
-0.0==0.0はtrueとする。 - そうでなければ,二つの異なる浮動小数点値は,等価演算子では等しくないと見なされる。 特に,正の無限大を表す値及び負の無限大を表す一つの値が存在するならば,それぞれはそれ自身とだけ等価であり,及び他のすべての値とは不等価とする。
==演算子によって生成される値は,もしその左辺オぺランドの値が右辺オぺランドの値と等しいならば,trueとする。 そうでなければ,その結果はfalseとする。!=演算子によって生成される値は,もしその左辺オぺランドの値が右辺オぺランドの値と等しくないならば,trueとする。 そうでなければ,その結果はfalseとする。
15.21.2 論理型等価演算子 == 及び !=
もし等価演算子のオペランドが両方とも型 boolean であるならば,その演算は論理型等価とする。
boolean 等価演算子は,結合的とする。
== の結果は,もしそのオぺランドが両方とも true 又は 両方とも true であるならば,true とする。
そうでなければ,その結果は false とする。
!= の結果は,もしそのオぺランドが両方とも true 又は両方とも true であるならば,false とする。
そうでなければ,その結果は true とする。
したがって,!= は,論理型オぺランドに適用するときに ^(15.22.2)と同様に振る舞う。
15.21.3 参照型等価演算子 == 及び !=
もし等価演算子のオペランドの型が両方ともに参照型又は空であるならば,その演算はオブジェクト等価とする。もしどちらか一方のオぺランドの型を他方のオぺランドの型にキャスト変換(5.5)によって変換することが不可能であるならば,コンパイル時エラーが発生する。 その二つのオぺランドの実行時の値は,必然的に不等価とする。
実行時には,== の結果は,そのオぺランドの値が両方とも null,両方とも同じオブジェクト若しくは配列を参照しているならば,true とする。
そうでなければ,その結果はfalseとする。
!= の結果は,もしそのオぺランドの値が両方とも null 又は両方とも同じオブジェクト若しくは配列を参照していれば,false とする。
そうでなければ,その結果はtrueとする。
== は,型 String への参照の比較に使用してもよいが,そのような等価試験は,その二つのオぺランドが同じオブジェクト String を参照しているかどうかを決定する。
もしそのオぺランドが違うオブジェクト String であるならば,それらが同じ文字の並びを含んでいたとしても,その結果はfalseとする。
二つの文字列 s 及び t の内容は,メソッド呼出し s.equals(t) によって試験することができる。
3.10.5も参照すること。
15.22 ビット単位及び論理演算子
ビット単位の演算子 (bitwise operators) 及び 論理演算子 (logical operators) は,AND演算子&,XOR演算子 ^ 及びOR演算子| を含む。
これらの演算子は,異なる優先度をもち,& は最大の優先度をもち,| は最小の優先度をもつ。
これらの演算子は各々構文的に左結合とする(各々左から右へとグループ化する。)。
各々の演算子は,もしそのオペランド式がどんな副作用ももたなければ,可換的とする。
各々の演算子は結合的とする。
AndExpression: EqualityExpression AndExpression & EqualityExpression ExclusiveOrExpression: AndExpression ExclusiveOrExpression ^ AndExpression InclusiveOrExpression: ExclusiveOrExpression InclusiveOrExpression | ExclusiveOrExpressionビット単位及び論理演算子は,数値型の二つのオペランド又は型
boolean の二つのオペランドを比較するのに使用してよい。
他のすべての場合はコンパイル時エラーになる。15.22.1 整数値ビット単位演算子 &,^及び|
演算子 &,^ 又は | の両オペランドがプリミティブ整数型であるとき,最初にオペランドに二項数値昇格(5.6.2)を実行する。
ビット単位の演算子式の型は,そのオペランドの昇格された型とする。
&に関しては,その結果値はオペランド値のビット単位のANDとする。
^に関しては,その結果値はオペランド値のビット単位のXORとする。
|に関しては,その結果値はオペランド値のビット単位のORとする。
例えば,式 0xff00&0xf0f0 の結果は 0xf000 とする。
0xff00^0xf0f0 の結果は 0x0ff0 とする。
0xff00|0xf0f0 の結果は 0xfff0 とする。
15.22.2 論理型論理演算子 &,^及び|
演算子 &,^ 及び | の両方のオペランドが型booleanであるとき,そのビット単位の演算子式の型は型 boolean とする。
& に関しては,もし両方のオペランド値が true であるならば,その結果値は true とする。
そうでなければ,その結果値は false とする。
^ に関しては,もしそのオペランド値が異なっているならば,その結果値はtrueとする。
そうでなければ,その結果値はfalseとする。
| に関しては,もし両方のオペランド値が false であるならば,その結果値は false とする。
そうでなければ,結果値は true とする。
15.23 条件AND演算子 &&
&& 演算子は,& (15.22.2)と類似しているが,しかしその左辺オペランド値が true である場合に限り,その右辺オペランドを評価する。
それは構文的に左結合とする(左から右へとグループ化する。)。
副作用及び結果値の両方に関して,完全に結合的とする。
つまり,任意の式 a,b 及び c に対して,式 ((a)&&(b))&&(c) の評価は,同じ副作用が同じ順序で発生し,式 (a)&&((b)&&(c)) の評価と同じ結果を生じる。
ConditionalAndExpression: InclusiveOrExpression ConditionalAndExpression && InclusiveOrExpression
&& のそれぞれのオペランドは,型 boolean でなければならない。
そうでなければ,コンパイル時エラーが発生する。
条件AND式の型は,常に boolean とする。
実行時に,左辺オペランド式を最初に評価する。
もしその値が false であるならば,条件AND式の値は false であり,その右辺オペランド式は評価されない。
もしその左辺オペランドの値が true であるならば,その右辺オペランド式を評価し,その値は条件AND式の値とする。
したがって,&& は,boolean オペランドに対して& と同じ結果を計算する。
その右辺オペランド式を,常にではなく条件的に評価するという点だけが異なる。
15.24 条件OR演算子 ||
演算子 || は | (15.22.2) と類似しているが,その左辺オペランドの値が false の場合に限り,その右辺オペランドを評価する。
それは構文的には左結合とする(左から右へとグループ化する。)。
副作用及び結果値の両方に関して,完全に結合的とする。
つまり,任意の式 a,b 及び c に対して,式 ((a)||(b))||(c) の評価は,同じ副作用が同じ順序で発生し,式 (a)||((b)||(c)) の評価と同じ結果を生じる。
ConditionalOrExpression: ConditionalAndExpression ConditionalOrExpression || ConditionalAndExpression
|| のそれぞれのオペランドは,型 boolean でなければならない。
そうでなければ,コンパイル時エラーが発生する。
条件OR式の型は,常に boolean とする。
実行時には,その左辺オペランド式が最初に評価される。
もしその値が true であるならば,その条件OR式の値は true であり,その右辺オペランド式は評価しない。
もしその左辺オペランドの値が false であるならば,その右辺オペランド式を評価し,その値は条件OR式の値になる。
したがって,|| は boolean オペランドに対して | と同じ結果を計算する。
その右辺オペランド式を常にではなく条件的に評価する点だけが異なる。
15.25 条件演算子 ? :
条件演算子 ? : は,二つの式のどちらを評価するのがよいかを決定するために,一つの式の論理値を使用する。
条件演算子は,構文的には右結合とする(右から左へとグループ化する。)。
そこで,a?b:c?d:e?f:g は,a?b:(c?d:(e?f:g)) と同じことを意味する。
ConditionalExpression: ConditionalOrExpression ConditionalOrExpression ? Expression : ConditionalExpression条件演算子は,三つのオペランド式をもつ。 1番目と2番目の式との間に
? が現れ,2番目と3番目の式の間に : が現れる。
最初の式は,型 boolean でなければならない。
そうでなければ,コンパイル時エラーが発生する。
条件演算子は,数値型の2番目と3番目のオペランドの選択,型 boolean の2番目と3番目のオペランドの選択,又はそれぞれが参照型か空型のいずれかである2番目と3番目のオペランドの選択に使用してよい。
他のすべての場合には,コンパイル時エラーになる。
void メソッドの呼出しは,2番目のオペランド式も3番目のオペランド式も許されないことに注意すること。
実際に,条件式は,void メソッドの起動が出現するかもしれないいかなる文脈にも出現することは許されない(14.8)。
- もし2番目及び3番目のオペランドが同じ型(空型であってもよい)をもつならば,その型は条件式の型とする。
- そうでなければ,もし2番目及び3番目のオペランドが数値型をもつならば,次の幾つかの場合がある。
- もしそのオペランドの一つが型
byteであり及び他方が型shortであるならば,その条件式の型はshortとする。 - もしそのオペランドの一つが型 T,ここで型 T は
byte,short又はcharである,及び他方のオペランドがその値が型Tで表現可能な型intの定数式であるならば,その条件式の型は T とする。 - そうでなければ,二項数値昇格(5.6.2)がそのオペランド型に適用され,その条件式の型は2番目及び3番目のオペランドの昇格された型とする。 二項数値昇格は,数値集合変換(5.1.8)を実行することに注意すること。
- もしそのオペランドの一つが型
- もしその2番目及び3番目のオペランドの一つが空型であり及び他方の型が参照型であるならば,その条件式の型はその参照型とする。
- もし2番目及び3番目のオペランドが異なる参照型であるならば,その型の一つが他の型(これをこの後はTと呼ぶ)に代入変換(5.2)によって変換可能でなければならない。 その条件式の型は T とする。 もしどちらの型も他方の型に代入互換でないならば,コンパイル時エラーとする。
boolean 値は,2番目又は3番目のオペランド式のどちらを選択するために使用される。その選択されたオペランド式を評価し,その結果の値は上述した規則によって決定される条件式の型に変換される。 選択されないオペランド式は,条件式のこの特定の評価のためには評価しない。
15.26 代入演算子
12個の代入演算子 (assignment operators) がある。 すべてが構文的に右結合とする(右から左へとグループ化する。)。 したがって,a=b=c は a=(b=c) を意味する。
これは c の値を b に割り当て,次に b の値を a に割り当てる。
AssignmentExpression: ConditionalExpression Assignment Assignment: LeftHandSide AssignmentOperator AssignmentExpression LeftHandSide: ExpressionName FieldAccess ArrayAccess AssignmentOperator: one of = *= /= %= += -= <<= >>= >>>= &= ^= |=代入演算子の最初のオペランドの結果は変数でなければならない。 そうでなければ,コンパイル時エラーが発生する。 このオペランドは,現在のオブジェクト又はクラスの局所変数又はフィールドの名前付けされた変数であってもよく,フィールドアクセス(15.11)又は配列アクセス(15.13)から生じ得るような計算された変数であってもよい。 代入式の型はその変数の型とする。
実行時には,その代入式の結果は代入が起こった後の変数の値とする。 代入式の結果自身は,変数ではない。
final と宣言された変数は,(それが未初期化最終変数(4.5.4)でない限り)代入できない。
なぜならば,final 変数のアクセスが式として使用されるときに,その結果は値であり変数ではないので,代入演算子の最初のオペランドとして使用することはできない。
15.26.1 単純代入演算子 =
もし代入変換(5.2)によって,その右辺オペランドの型をその変数の型に変換できないならば,コンパイル時エラーが発生する。実行時には,式は次に述べる二つの方法の中の一つで評価する。 もしその左辺オペランド式が配列アクセス式でないならば,次の三段階が要求される。
- 最初に,変数を生成するために,その左辺オペランドが評価される。 もしこの評価が中途完了するならば,その代入式は同じ理由で中途完了する。 したがって,その右辺オペランドは評価されず,代入は起こらない。
- そうでなければ,その右辺オペランドが評価される。 もしこの評価が中途完了するならば,その代入式は同じ理由で中途完了し,代入は起こらない。
- そうでなければ,適切な(指数部拡張数値集合ではなく)標準数値集合に数値集合変換(5.1.8)をおこなうために,その右辺オペランドの値をその左辺変数の型に変換し,及びその変換結果を変数に記憶する。
- 最初に,その左辺オペランドの配列アクセス式の配列参照副式が評価される。 もしこの評価が中途完了するならば,その代入式は同じ理由で中途完了する。 (左辺オペランド配列アクセス式の)インデクス副式及び右辺オペランドは評価されず,代入は起こらない。
- そうでなければ,その左辺オペランド配列アクセス式のインデクス副式を評価する。 この評価が中途完了するならば,代入式は同じ理由で中途完了し,右辺オペランドを評価せず,代入は起こらない。
- そうでなければ,その右辺オペランドを評価する。 もしこの評価が中途完了するならば,その代入式は同じ理由で中途完了し,代入は起こらない。
- そうでなければ,もし配列参照副式の値が
nullであるならば,代入は起こらず,NullPointerExceptionが投げられる。 - そうでなければ,配列参照副式の値は実際には配列を参照する。
もしそのインデクス副式の値がゼロ未満又は配列の長さ以上であるならば,代入は起こらず,
IndexOutOfBoundsExceptionが投げられる。 - そうでなければ,そのインデクス副式の値は,配列参照副式の値によって参照される配列の構成要素を選択するために使用される。
この構成要素は変数であり,その型を SC と呼ぶ。
TC をコンパイル時に決定される代入演算子の左辺オペランドの型であると仮定する。
- もし TC がプリミティブ型であるならば,SC は必然的に TC と同じとする。 その右辺オペランドの値は,(指数部拡張数値集合をのぞく)適切な標準数値集合への数値集合変換(5.1.8)のためにその選択された配列の構成要素の型に変換され,及びその変換の結果は選択した配列の構成要素に記憶される。
- もし TC が参照型であるならば,SC は TC と同じではないかもしれず,TCを拡張又は実装した型かもしれない。
RC は,実行時に右辺のオペランドの値を参照するオブジェクトのクラスであると仮定する。
コンパイラは,その配列の構成要素が厳密に型TCであることをコンパイル時に証明してもよい(例えば,TC が,finalであるかもしれない)。 しかし,もしコンパイラがコンパイル時に配列の構成要素が厳密に型 TC であることを証明できないならば,実行時にクラスRCが配列の構成要素の実際の型 SC と代入互換(5.2)であることを保証するために,検査がおこなわなければならない。 この検査は,検査が失敗した場合にClassCastExceptionではなくArrayStoreExceptionが投げられることを除けば,縮小キャスト(5.5, 15.16)に似ている。 したがって,次のようになる。
class ArrayReferenceThrow extends RuntimeException { }
class IndexThrow extends RuntimeException { }
class RightHandSideThrow extends RuntimeException { }
class IllustrateSimpleArrayAssignment {
static Object[] objects = { new Object(), new Object() };
static Thread[] threads = { new Thread(), new Thread() };
static Object[] arrayThrow() {
throw new ArrayReferenceThrow();
}
static int indexThrow() { throw new IndexThrow(); }
static Thread rightThrow() {
throw new RightHandSideThrow();
}
static String name(Object q) {
String sq = q.getClass().getName();
int k = sq.lastIndexOf('.');
return (k < 0) ? sq : sq.substring(k+1);
}
static void testFour(Object[] x, int j, Object y) {
String sx = x == null ? "null" : name(x[0]) + "s";
String sy = name(y);
System.out.println();
try {
System.out.print(sx + "[throw]=throw => ");
x[indexThrow()] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[throw]=" + sy + " => ");
x[indexThrow()] = y;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]=throw => ");
x[j] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]=" + sy + " => ");
x[j] = y;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
}
public static void main(String[] args) {
try {
System.out.print("throw[throw]=throw => ");
arrayThrow()[indexThrow()] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[throw]=Thread => ");
arrayThrow()[indexThrow()] = new Thread();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]=throw => ");
arrayThrow()[1] = rightThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]=Thread => ");
arrayThrow()[1] = new Thread();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
testFour(null, 1, new StringBuffer());
testFour(null, 1, new StringBuffer());
testFour(null, 9, new Thread());
testFour(null, 9, new Thread());
testFour(objects, 1, new StringBuffer());
testFour(objects, 1, new Thread());
testFour(objects, 9, new StringBuffer());
testFour(objects, 9, new Thread());
testFour(threads, 1, new StringBuffer());
testFour(threads, 1, new Thread());
testFour(threads, 9, new StringBuffer());
testFour(threads, 9, new Thread());
}
}
この多くの中で最も興味深い場合は,最後から13番目とする。throw[throw]=throw => ArrayReferenceThrow throw[throw]=Thread => ArrayReferenceThrow throw[1]=throw => ArrayReferenceThrow throw[1]=Thread => ArrayReferenceThrow null[throw]=throw => IndexThrow null[throw]=StringBuffer => IndexThrow null[1]=throw => RightHandSideThrow null[1]=StringBuffer => NullPointerException null[throw]=throw => IndexThrow null[throw]=StringBuffer => IndexThrow null[1]=throw => RightHandSideThrow null[1]=StringBuffer => NullPointerException null[throw]=throw => IndexThrow null[throw]=Thread => IndexThrow null[9]=throw => RightHandSideThrow null[9]=Thread => NullPointerException null[throw]=throw => IndexThrow null[throw]=Thread => IndexThrow null[9]=throw => RightHandSideThrow null[9]=Thread => NullPointerException Objects[throw]=throw => IndexThrow Objects[throw]=StringBuffer => IndexThrow Objects[1]=throw => RightHandSideThrow Objects[1]=StringBuffer => Okay! Objects[throw]=throw => IndexThrow Objects[throw]=Thread => IndexThrow Objects[1]=throw => RightHandSideThrow Objects[1]=Thread => Okay! Objects[throw]=throw => IndexThrow Objects[throw]=StringBuffer => IndexThrow Objects[9]=throw => RightHandSideThrow Objects[9]=StringBuffer => ArrayIndexOutOfBoundsException Objects[throw]=throw => IndexThrow Objects[throw]=Thread => IndexThrow Objects[9]=throw => RightHandSideThrow Objects[9]=Thread => ArrayIndexOutOfBoundsException Threads[throw]=throw => IndexThrow Threads[throw]=StringBuffer => IndexThrow Threads[1]=throw => RightHandSideThrow Threads[1]=StringBuffer => ArrayStoreException Threads[throw]=throw => IndexThrow Threads[throw]=Thread => IndexThrow Threads[1]=throw => RightHandSideThrow Threads[1]=Thread => Okay! Threads[throw]=throw => IndexThrow Threads[throw]=StringBuffer => IndexThrow Threads[9]=throw => RightHandSideThrow Threads[9]=StringBuffer => ArrayIndexOutOfBoundsException Threads[throw]=throw => IndexThrow Threads[throw]=Thread => IndexThrow Threads[9]=throw => RightHandSideThrow Threads[9]=Thread => ArrayIndexOutOfBoundsException
これはThreads[1]=StringBuffer => ArrayStoreException
StringBuffer への参照を,構成要素が型 Thread である配列に記憶しようとして,ArrayStoreExceptionを投げたことを示す。
そのコードは,コンパイル時には正しい型とする。
その代入は,型 Object[] の左辺及び型 Object の右辺をもつ。
実行時には,メソッド testFour への最初の実引数は,"Threadの配列"のインスタンスへの参照であり,及び3番目の実引数は,クラス StringBuffer のインスタンスへの参照とする。
15.26.2 複合代入演算子
+= を除くすべての複合代入演算子は,両方のオペランドがプリミティブ型であることを要求される。
+=に対しては,もしその左辺オペランドが型 String であれば,その右辺オペランドはどの型でもよい。
形式 E1op=E2 の複合代入式は,もとの式は E1 を一度だけ評価する点を除き,E1=(T)((E1)op(E2)) に等価とする。
ここで,T は E1の型とする。
型 T への暗黙のキャストは,等値変換(5.1.1)又はプリミティブ型の縮小変換(5.1.3)のどちらでもよいことに注意すること。
例えば,次のコードは正しい。
short x = 3; x += 4.6;及び,これは次の例とは同等であるので,
x は値 7 をもつ。
short x = 3; x = (short)(x + 4.6);実行時に,その式は二つの方法の中の一つで評価される。 もしその左辺オペランド式が配列アクセス式でないならば,次の四つの段階が要求される。
- 最初に,変数を生成するために,その左辺オペランドが評価される。 もしこの評価が中途完了するならば,その代入式は同じ理由で中途完了する。 その右辺オペランドは評価されず,代入は起こらない。
- そうでなければ,その左辺オペランドの値が保存され,その右辺オペランドが評価される。 もしこの評価が中途完了するならば,その代入式は同じ理由で中途完了し,代入は起こらない。
- そうでなければ,その左辺変数の保存された値及びその右辺オペランドの値が,複合代入演算子によって示される二項演算を実行するために使用される。 もしこの演算が突然に中途完了すれば(唯一の可能性はゼロによる整数除算,15.17.2参照),代入式は同じ理由で中途完了し,代入は起こらない。
- そうでなければ,適切な標準数値集合(指数部拡張数値集合ではない)に数値集合変換(5.1.8)するために,その二項演算の結果がその左辺変数の型に変換され,その変換結果が変数に記憶される。
- 最初に,その左辺オペランドの配列アクセス式の配列参照副式が評価される。 もしこの評価が中途完了すれば,その代入式は同じ理由で中途完了する。 (左辺オペランド配列アクセス式の)インデクス副式及び右辺オペランドは評価されず,代入は起こらない。
- そうでなければ,その左辺オペランドの配列アクセス式のインデクス副式を評価する。 もしこの評価が中途完了するならば,その代入式は同じ理由で中途完了し,その右辺オペランドは評価されず,代入は起こらない。
- そうでなければ,もし配列参照副式が
nullであるならば,代入は起こらず,NullPointerExceptionが投げられる。 - そうでなければ,その配列参照副式の値は実際には配列を参照する。
もしそのインデクス副式の値がゼロ未満又は配列の長さ以上であるならば,代入は起こらず,
ArrayIndexOutOfBoundsExceptionが投げられる。 - そうでなければ,そのインデクス副式の値は,配列参照副式の値によって参照される配列の構成要素を選択するために使用される。 この構成要素の値は保存され,次にその右辺オペランドが評価される。 もしこの評価が中途完了するならば,その代入式は同じ理由で中途完了し,代入は起こらない (単純代入演算子では,その右辺オペランドの評価は,その配列参照副式及びインデクス副式の検査の前に行われるが,複合代入演算子では,その右辺オペランドの評価は,これらの検査の後に行われる。)。
- そうでなければ,その値を保存する前の段階で選択された配列の構成要素を考える。
この構成要素は変数であり,その型を S と呼ぶ。
また,T をコンパイル時に決定されるその代入演算子の左辺オペランドの型であると仮定する。
- もし T がプリミティブ型であるならば,S は必然的に T と同じでなる。
- その配列の構成要素の保存された値及びその右辺オペランドの値が,複合代入演算子により示された二項演算を実行するのに使用される。 もしこの演算が中途完了するならば(唯一の可能性はゼロによる整数除算,15.17.2参照),その代入式は同じ理由で中途完了し,代入は起こらない。
- そうでなければ,適切な標準数値集合(指数部拡張数値集合ではない)への数値集合変換(5.1.8)をおこなうために,その二項演算の結果は選択された配列の構成要素の型に変換され,その変換の結果は配列の構成要素に記憶される。
- もしTが参照型であるならば,それは
Stringでなければならない。 クラスStringはfinal宣言されたクラスなので,S もまたStringでなければならない。 したがって,単純代入演算子では時々必要になる実行時検査は,複合代入演算子に対しては決して要求されない。
- もし T がプリミティブ型であるならば,S は必然的に T と同じでなる。
String の結果を,その配列の構成要素に記憶する。配列の構成要素への複合代入の規則を,次のプログラム例で示す。
class ArrayReferenceThrow extends RuntimeException { }
class IndexThrow extends RuntimeException { }
class RightHandSideThrow extends RuntimeException { }
class IllustrateCompoundArrayAssignment {
static String[] strings = { "Simon", "Garfunkel" };
static double[] doubles = { Math.E, Math.PI };
static String[] stringsThrow() {
throw new ArrayReferenceThrow();
}
static double[] doublesThrow() {
throw new ArrayReferenceThrow();
}
static int indexThrow() { throw new IndexThrow(); }
static String stringThrow() {
throw new RightHandSideThrow();
}
static double doubleThrow() {
throw new RightHandSideThrow();
}
static String name(Object q) {
String sq = q.getClass().getName();
int k = sq.lastIndexOf('.');
return (k < 0) ? sq : sq.substring(k+1);
}
static void testEight(String[] x, double[] z, int j) {
String sx = (x == null) ? "null" : "Strings";
String sz = (z == null) ? "null" : "doubles";
System.out.println();
try {
System.out.print(sx + "[throw]+=throw => ");
x[indexThrow()] += stringThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sz + "[throw]+=throw => ");
z[indexThrow()] += doubleThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[throw]+=\"heh\" => ");
x[indexThrow()] += "heh";
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sz + "[throw]+=12345 => ");
z[indexThrow()] += 12345;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]+=throw => ");
x[j] += stringThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sz + "[" + j + "]+=throw => ");
z[j] += doubleThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sx + "[" + j + "]+=\"heh\" => ");
x[j] += "heh";
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print(sz + "[" + j + "]+=12345 => ");
z[j] += 12345;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
}
public static void main(String[] args) {
try {
System.out.print("throw[throw]+=throw => ");
stringsThrow()[indexThrow()] += stringThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[throw]+=throw => ");
doublesThrow()[indexThrow()] += doubleThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[throw]+=\"heh\" => ");
stringsThrow()[indexThrow()] += "heh";
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[throw]+=12345 => ");
doublesThrow()[indexThrow()] += 12345;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]+=throw => ");
stringsThrow()[1] += stringThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]+=throw => ");
doublesThrow()[1] += doubleThrow();
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]+=\"heh\" => ");
stringsThrow()[1] += "heh";
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
try {
System.out.print("throw[1]+=12345 => ");
doublesThrow()[1] += 12345;
System.out.println("Okay!");
} catch (Throwable e) { System.out.println(name(e)); }
testEight(null, null, 1);
testEight(null, null, 9);
testEight(strings, doubles, 1);
testEight(strings, doubles, 9);
}
}
この多くの中で最も興味深い場合は,最後から11番目及び12番目とする。throw[throw]+=throw => ArrayReferenceThrow throw[throw]+=throw => ArrayReferenceThrow throw[throw]+="heh" => ArrayReferenceThrow throw[throw]+=12345 => ArrayReferenceThrow throw[1]+=throw => ArrayReferenceThrow throw[1]+=throw => ArrayReferenceThrow throw[1]+="heh" => ArrayReferenceThrow throw[1]+=12345 => ArrayReferenceThrow null[throw]+=throw => IndexThrow null[throw]+=throw => IndexThrow null[throw]+="heh" => IndexThrow null[throw]+=12345 => IndexThrow null[1]+=throw => NullPointerException null[1]+=throw => NullPointerException null[1]+="heh" => NullPointerException null[1]+=12345 => NullPointerException null[throw]+=throw => IndexThrow null[throw]+=throw => IndexThrow null[throw]+="heh" => IndexThrow null[throw]+=12345 => IndexThrow null[9]+=throw => NullPointerException null[9]+=throw => NullPointerException null[9]+="heh" => NullPointerException null[9]+=12345 => NullPointerException Strings[throw]+=throw => IndexThrow doubles[throw]+=throw => IndexThrow Strings[throw]+="heh" => IndexThrow doubles[throw]+=12345 => IndexThrow Strings[1]+=throw => RightHandSideThrow doubles[1]+=throw => RightHandSideThrow Strings[1]+="heh" => Okay! doubles[1]+=12345 => Okay! Strings[throw]+=throw => IndexThrow doubles[throw]+=throw => IndexThrow Strings[throw]+="heh" => IndexThrow doubles[throw]+=12345 => IndexThrow Strings[9]+=throw => ArrayIndexOutOfBoundsException doubles[9]+=throw => ArrayIndexOutOfBoundsException Strings[9]+="heh" => ArrayIndexOutOfBoundsException doubles[9]+=12345 => ArrayIndexOutOfBoundsException
これらは,例外を投げることができる右辺が実際に例外を投げた場合で,さらに多くの中で唯一の場合とする。 これは,本当に,空配列参照値及び領域外インデクス値の検査後に,その右辺オペランドの評価が起こることを示している。Strings[1]+=throw => RightHandSideThrow doubles[1]+=throw => RightHandSideThrow
次のプログラムは,右辺を評価する前に複合代入の左辺の値が保存される事実を示す。
class Test {
public static void main(String[] args) {
int k = 1;
int[] a = { 1 };
k += (k = 4) * (k + 2);
a[0] += (a[0] = 4) * (a[0] + 2);
System.out.println("k==" + k + " and a[0]==" + a[0]);
}
}
その右辺オペランドk==25 and a[0]==25
(k=4)*(k+2) が評価される前に,k の値 1 が複合代入演算子 += により保存される。
この右辺オペランドの評価は,4 を k に割り当て,k+2 を値 6 と計算し,4 に 6 をかけて 24 を得る。
これに保存した値 1 を加えて,25 を得る。
さらにこの値が演算子 += によって k に記憶される。
同じ分析が,a[0] を使用する場合に適用される。
結局,次の文は,
次の文と正確に同じように振舞う。k += (k = 4) * (k + 2); a[0] += (a[0] = 4) * (a[0] + 2);
k = k + (k = 4) * (k + 2); a[0] = a[0] + (a[0] = 4) * (a[0] + 2);
15.27 式
式 (Expression) は,次のように任意の代入式とする。
Expression: AssignmentExpressionC及びC++と異なり,Javaプログラム言語にはコンマ演算子は存在しない。
15.28 定数式
ConstantExpression: Expressionコンパイル時の定数式 (constant expression) は,次のものだけを使用して構成されるプリミティブ型の値又は
String を表す式とする。
- プリミティブ型のリテラル及び型
Stringのリテラル - プリミティブ型へのキャスト又は型
Stringへのキャスト - 単項演算子
+,-,~及び!(しかし,++又は--は含まない) - 乗除演算子
*,/及び% - 加減演算子
+及び- - シフト演算子
<<,>>及び>>> - 関係演算子
<,<=,>及び>=(しかし,instanceofは含まない) - 等値演算子
==及び!= - ビット単位論理演算子
&,^及び| - 条件AND演算子
&&及び条件OR演算子|| - 三項条件演算子
?: - 初期化子が定数式である
final変数を参照する単純名 - 初期化子が定数式である
final変数を参照する形式 TypeName.Identifier の限定名
switch文(14.10)内のcase内で使用し,代入変換(5.2)に対して特別な意味をもつ。コンパイル時の定数式は,FP厳密であることを考慮しなくてよい非定数式中に出現した場合でさえも,常にFP厳密(15.4)として処理される。
true (short)(1*2*3*4*5*6) Integer.MAX_VALUE / 2 2.0 * Math.PI "The integer " + Long.MAX_VALUE + " is mighty big."
| 目次 | 前 | 次 | 索引 | Java言語規定 第2版 |